 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Model Compression via Deep Reinforcement Learning
Paper and Code
Dec 04, 2019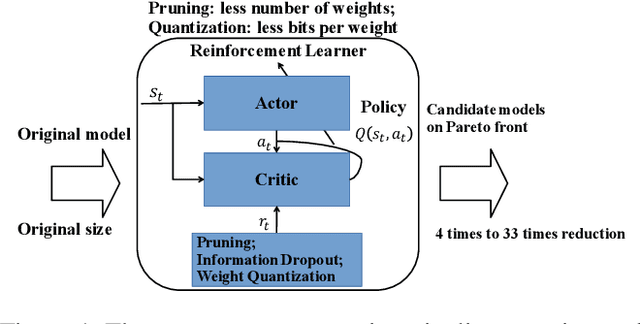
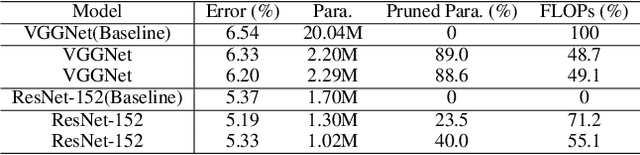
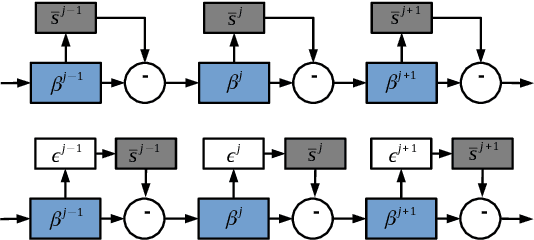
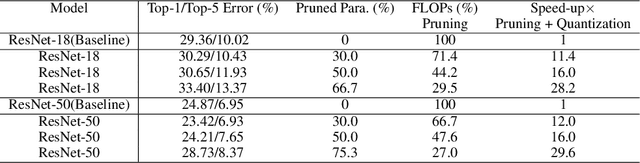
Besides accuracy, the storage of convolutional neural networks (CNN) models is another important factor considering limited hardware resources in practical applications. For example, autonomous driving requires the design of accurate yet fast CNN for low latency in object detection and classification. To fulfill the need, we aim at obtaining CNN models with both high testing accuracy and small size/storage to address resource constraints in many embedded systems. In particular, this paper focuses on proposing a generic reinforcement learning based model compression approach in a two-stage compression pipeline: pruning and quantization. The first stage of compression, i.e., pruning, is achieved via exploiting deep reinforcement learning (DRL) to co-learn the accuracy of CNN models updated after layer-wise channel pruning on a testing dataset and the FLOPs, number of floating point operations in each layer, updated after kernel-wise variational pruning using information dropout. Layer-wise channel pruning is to remove unimportant kernels from the input channel dimension while kernel-wise variational pruning is to remove unimportant kernels from the 2D-kernel dimensions, namely, height and width. The second stage, i.e., quantization, is achieved via a similar DRL approach but focuses on obtaining the optimal weight bits for individual layers. We further conduct experimental results on CIFAR-10 and ImageNet datasets. For the CIFAR-10 dataset, the proposed method can reduce the size of VGGNet by 9x from 20.04MB to 2.2MB with 0.2% accuracy increase. For the ImageNet dataset, the proposed method can reduce the size of VGG-16 by 33x from 138MB to 4.14MB with no accuracy loss.