 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Metric Learning with BIER: Boosting Independent Embeddings Robustly
Paper and Code
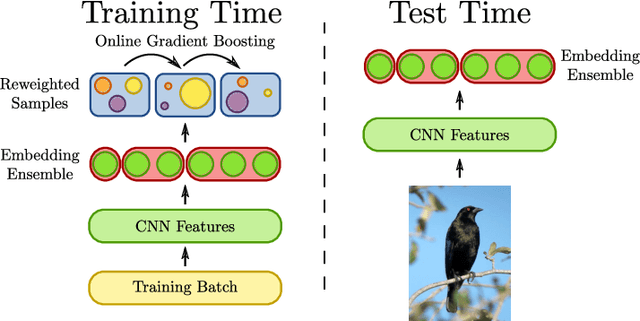
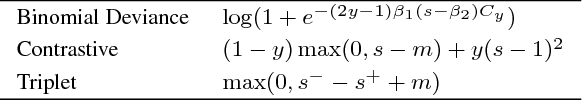
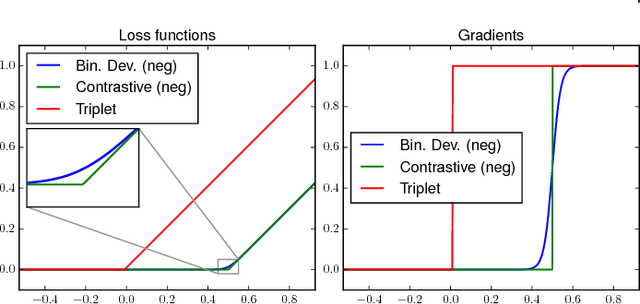
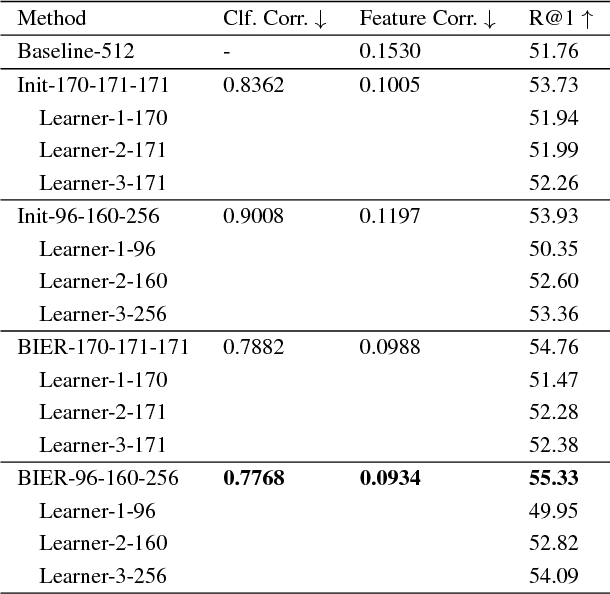
Learning similarity functions between image pairs with deep neural networks yields highly correlated activations of embeddings. In this work, we show how to improve the robustness of such embeddings by exploiting the independence within ensembles. To this end, we divide the last embedding layer of a deep network into an embedding ensemble and formulate training this ensemble as an online gradient boosting problem. Each learner receives a reweighted training sample from the previous learners. Further, we propose two loss functions which increase the diversity in our ensemble. These loss functions can be applied either for weight initialization or during training. Together, our contributions leverage large embedding sizes more effectively by significantly reducing correlation of the embedding and consequently increase retrieval accuracy of the embedding. Our method works with any differentiable loss function and does not introduce any additional parameters during test time. We evaluate our metric learning method on image retrieval tasks and show that it improves over state-of-the-art methods on the CUB 200-2011, Cars-196, Stanford Online Products, In-Shop Clothes Retrieval and VehicleID datasets.