 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Matching Autoencoders
Paper and Code
Nov 16, 2017
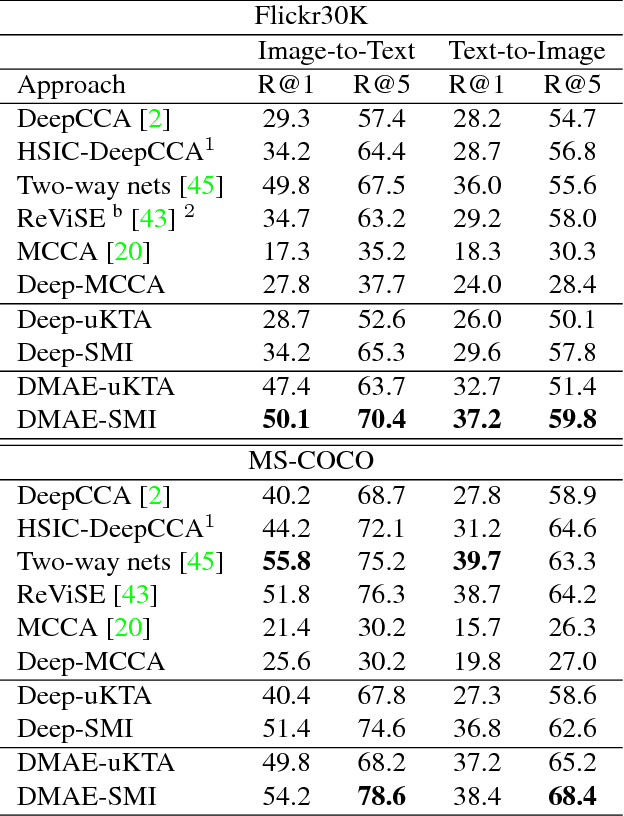

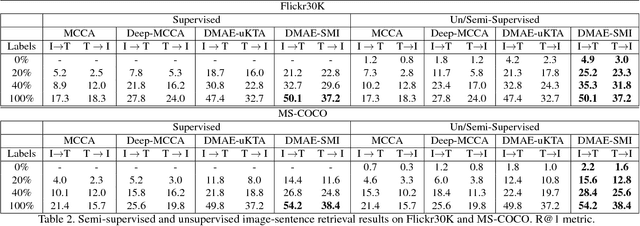
Increasingly many real world tasks involve data in multiple modalities or views. This has motivated the development of many effective algorithms for learning a common latent space to relate multiple domains. However, most existing cross-view learning algorithms assume access to paired data for training. Their applicability is thus limited as the paired data assumption is often violated in practice: many tasks have only a small subset of data available with pairing annotation, or even no paired data at all. In this paper we introduce Deep Matching Autoencoders (DMAE), which learn a common latent space and pairing from unpaired multi-modal data. Specifically we formulate this as a cross-domain representation learning and object matching problem. We simultaneously optimise parameters of representation learning auto-encoders and the pairing of unpaired multi-modal data. This framework elegantly spans the full regime from fully supervised, semi-supervised, and unsupervised (no paired data) multi-modal learning. We show promising results in image captioning, and on a new task that is uniquely enabled by our methodology: unsupervised classifier learning.