Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep linear neural networks with arbitrary loss: All local minima are global
Paper and Code
Jul 24, 2018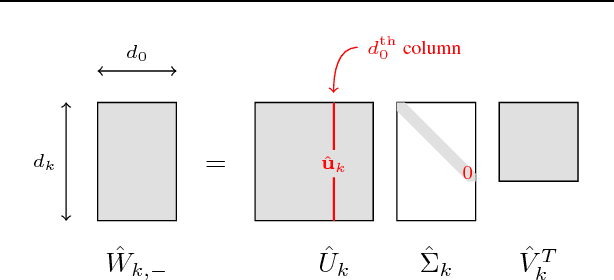
We consider deep linear networks with arbitrary convex differentiable loss. We provide a short and elementary proof of the fact that all local minima are global minima if the hidden layers are either 1) at least as wide as the input layer, or 2) at least as wide as the output layer. This result is the strongest possible in the following sense: If the loss is convex and Lipschitz but not differentiable then deep linear networks can have sub-optimal local minima.
View paper on