 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning is Singular, and That's Good
Paper and Code
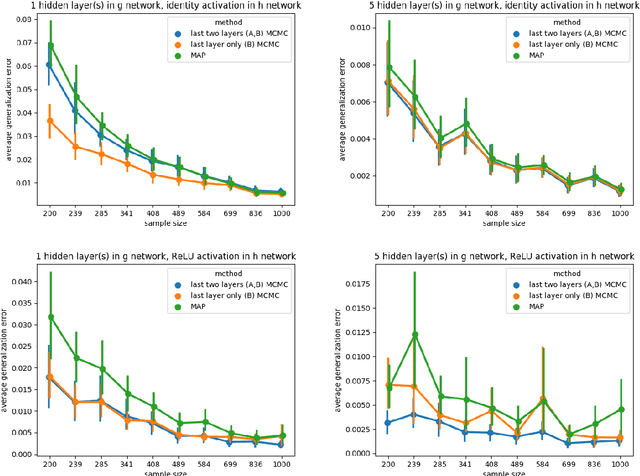

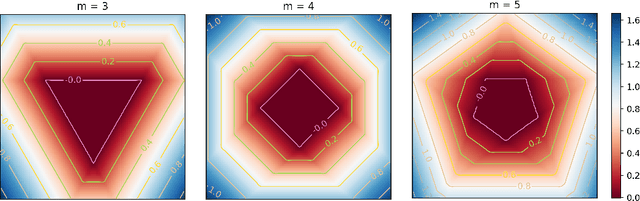

In singular models, the optimal set of parameters forms an analytic set with singularities and classical statistical inference cannot be applied to such models. This is significant for deep learning as neural networks are singular and thus "dividing" by the determinant of the Hessian or employing the Laplace approximation are not appropriate. Despite its potential for addressing fundamental issues in deep learning, singular learning theory appears to have made little inroads into the developing canon of deep learning theory. Via a mix of theory and experiment, we present an invitation to singular learning theory as a vehicle for understanding deep learning and suggest important future work to make singular learning theory directly applicable to how deep learning is performed in practice.