 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for Reference-Free Geolocation for Poplar Trees
Paper and Code
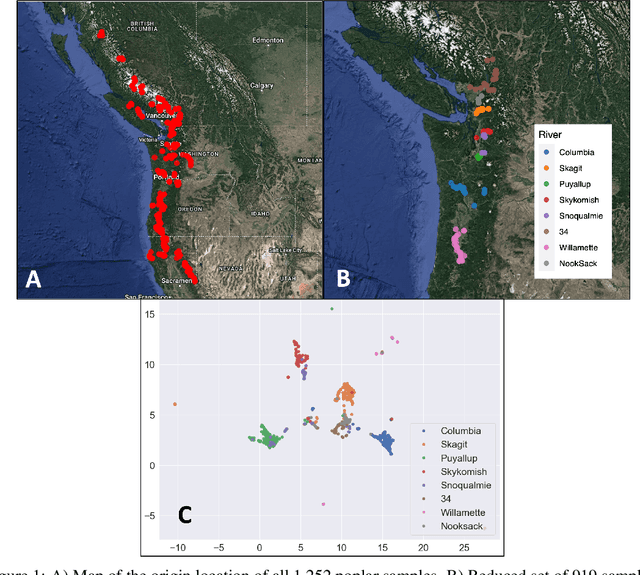
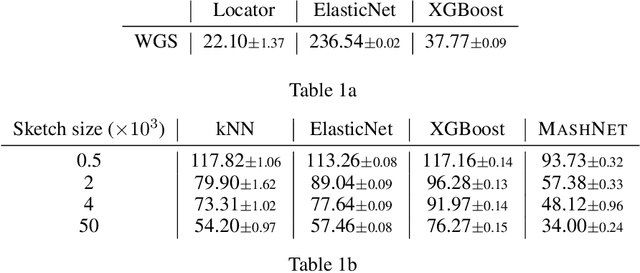
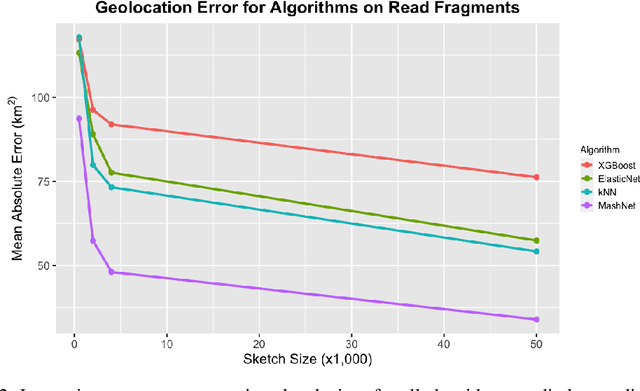
A core task in precision agriculture is the identification of climatic and ecological conditions that are advantageous for a given crop. The most succinct approach is geolocation, which is concerned with locating the native region of a given sample based on its genetic makeup. Here, we investigate genomic geolocation of Populus trichocarpa, or poplar, which has been identified by the US Department of Energy as a fast-rotation biofuel crop to be harvested nationwide. In particular, we approach geolocation from a reference-free perspective, circumventing the need for compute-intensive processes such as variant calling and alignment. Our model, MashNet, predicts latitude and longitude for poplar trees from randomly-sampled, unaligned sequence fragments. We show that our model performs comparably to Locator, a state-of-the-art method based on aligned whole-genome sequence data. MashNet achieves an error of 34.0 km^2 compared to Locator's 22.1 km^2. MashNet allows growers to quickly and efficiently identify natural varieties that will be most productive in their growth environment based on genotype. This paper explores geolocation for precision agriculture while providing a framework and data source for further development by the machine learning community.