 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning-based Single Image Face Depth Data Enhancement
Paper and Code
Jun 19, 2020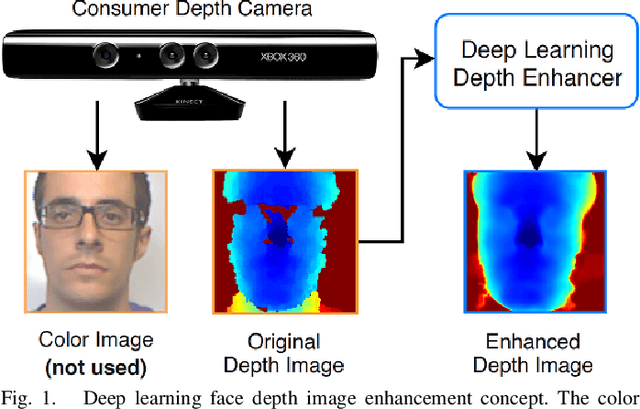
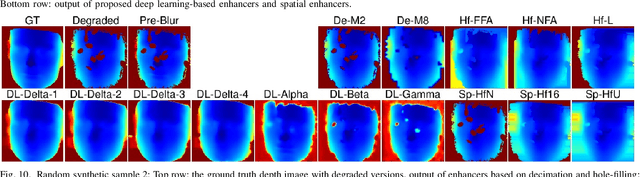
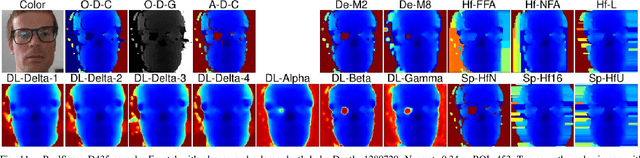
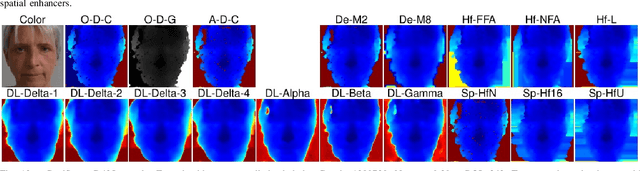
Face recognition can benefit from the utilization of depth data captured using low-cost cameras, in particular for presentation attack detection purposes. Depth video output from these capture devices can however contain defects such as holes, as well as general depth inaccuracies. This work proposes a deep learning-based face depth enhancement method. The trained artificial neural networks utilize U-Net-like architectures, and are compared against general enhancer types. All tested enhancer types exclusively use depth data as input, which differs from methods that enhance depth based on additional input data such as visible light color images. Due to the noted apparent lack of real-world camera datasets with suitable properties, face depth ground truth images and degraded forms thereof are synthesized with help of PRNet, both for the deep learning training and for an experimental quantitative evaluation of all enhancer types. Generated enhancer output samples are also presented for real camera data, namely custom RealSense D435 depth images and Kinect v1 data from the KinectFaceDB. It is concluded that the deep learning enhancement approach is superior to the tested general enhancers, without overly falsifying depth data when non-face input is provided.