 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning-based COVID-19 pneumonia classification using chest CT images: model generalizability
Paper and Code
Feb 18, 2021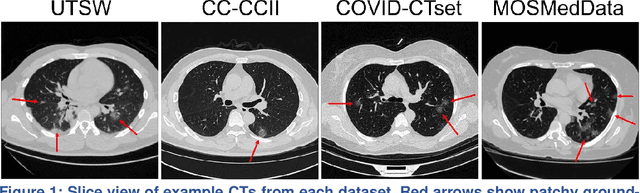
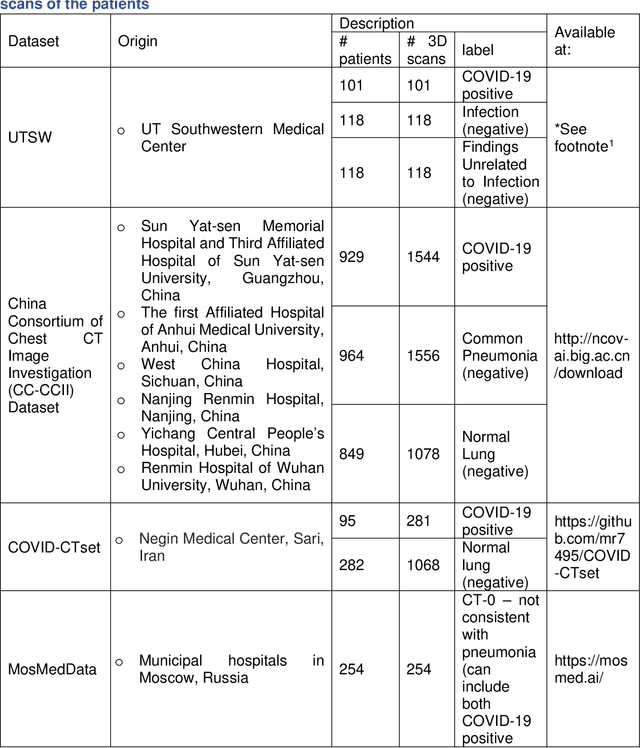
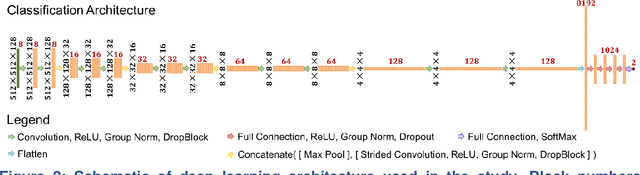
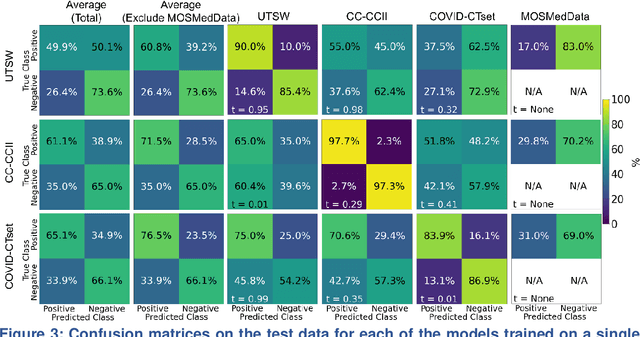
Since the outbreak of the COVID-19 pandemic, worldwide research efforts have focused on using artificial intelligence (AI) technologies on various medical data of COVID-19-positive patients in order to identify or classify various aspects of the disease, with promising reported results. However, concerns have been raised over their generalizability, given the heterogeneous factors in training datasets. This study aims to examine the severity of this problem by evaluating deep learning (DL) classification models trained to identify COVID-19-positive patients on 3D computed tomography (CT) datasets from different countries. We collected one dataset at UT Southwestern (UTSW), and three external datasets from different countries: CC-CCII Dataset (China), COVID-CTset (Iran), and MosMedData (Russia). We divided the data into 2 classes: COVID-19-positive and COVID-19-negative patients. We trained nine identical DL-based classification models by using combinations of the datasets with a 72% train, 8% validation, and 20% test data split. The models trained on a single dataset achieved accuracy/area under the receiver operating characteristics curve (AUC) values of 0.87/0.826 (UTSW), 0.97/0.988 (CC-CCCI), and 0.86/0.873 (COVID-CTset) when evaluated on their own dataset. The models trained on multiple datasets and evaluated on a test set from one of the datasets used for training performed better. However, the performance dropped close to an AUC of 0.5 (random guess) for all models when evaluated on a different dataset outside of its training datasets. Including the MosMedData, which only contained positive labels, into the training did not necessarily help the performance on the other datasets. Multiple factors likely contribute to these results, such as patient demographics and differences in image acquisition or reconstruction, causing a data shift among different study cohorts.