Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Impression: Audiovisual Deep Residual Networks for Multimodal Apparent Personality Trait Recognition
Paper and Code
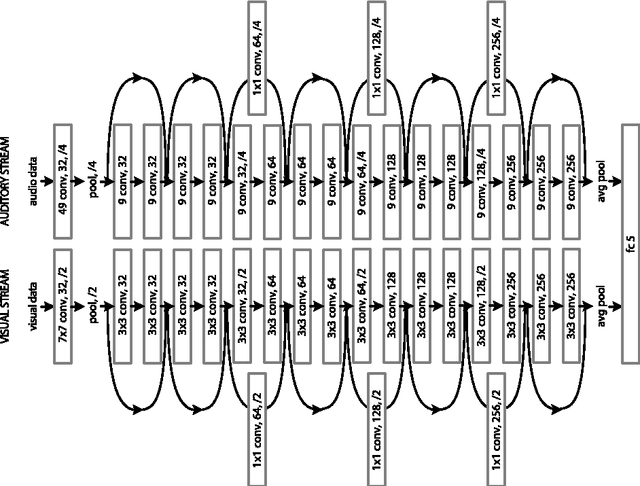

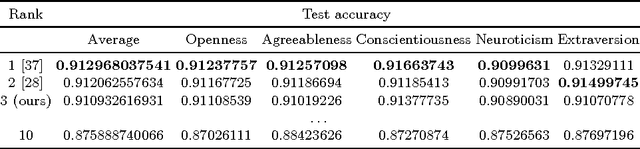

Here, we develop an audiovisual deep residual network for multimodal apparent personality trait recognition. The network is trained end-to-end for predicting the Big Five personality traits of people from their videos. That is, the network does not require any feature engineering or visual analysis such as face detection, face landmark alignment or facial expression recognition. Recently, the network won the third place in the ChaLearn First Impressions Challenge with a test accuracy of 0.9109.
View paper on