 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Dialog Act Recognition using Multiple Token, Segment, and Context Information Representations
Paper and Code
Jul 23, 2018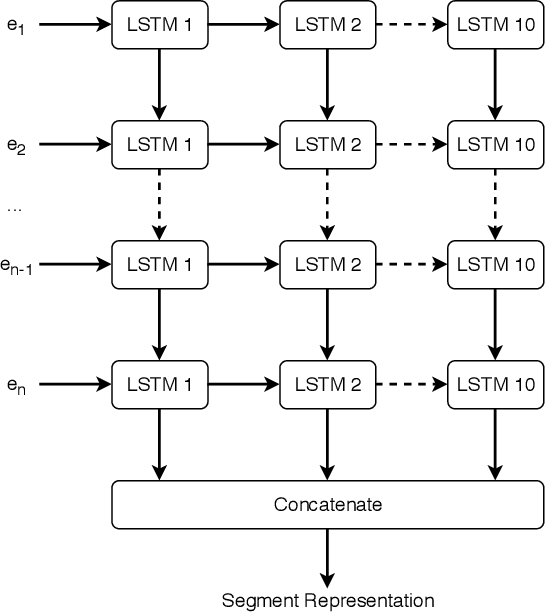
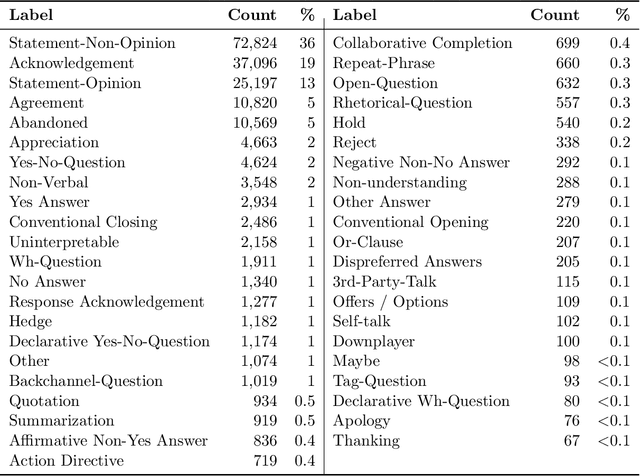
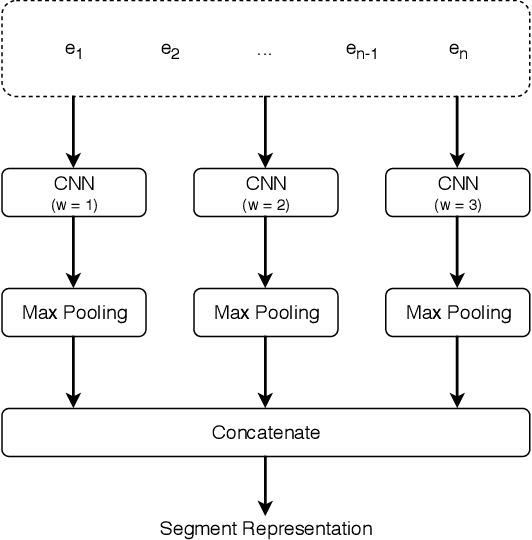
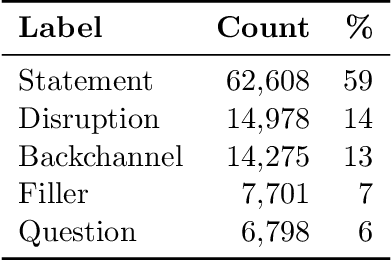
A dialog act is a representation of an intention transmitted in the form of words. In this sense, when someone wants to transmit some intention, it is revealed both in the selected words and in how they are combined to form a structured segment. Furthermore, the intentions of a speaker depend not only on her intrinsic motivation, but also on the history of the dialog and the expectation she has of its future. In this article we explore multiple representation approaches to capture cues for intention at different levels. Recent approaches on automatic dialog act recognition use Word2Vec embeddings for word representation. However, these are not able to capture segment structure information nor morphological traits related to intention. Thus, we also explore the use of dependency-based word embeddings, as well as character-level tokenization. To generate the segment representation, the top performing approaches on the task use either RNNs that are able to capture information concerning the sequentiality of the tokens or CNNs that are able to capture token patterns that reveal function. However, both aspects are important and should be captured together. Thus, we also explore the use of an RCNN. Finally, context information concerning turn-taking, as well as that provided by the surrounding segments has been proved important in previous studies. However, the representation approaches used for the latter in those studies are not appropriate to capture sequentiality, which is one of the most important characteristics of the segments in a dialog. Thus, we explore the use of approaches able to capture that information. By combining the best approaches for each aspect, we achieve results that surpass the previous state-of-the-art in a dialog system context and similar to human-level in an annotation context on the Switchboard Dialog Act Corpus, which is the most explored corpus for the task.