 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Auxiliary Learning for Visual Localization and Odometry
Paper and Code
Mar 09, 2018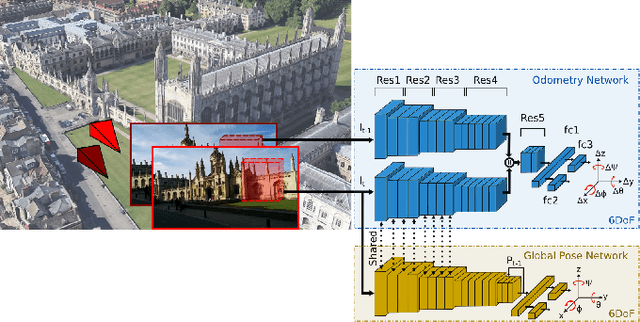


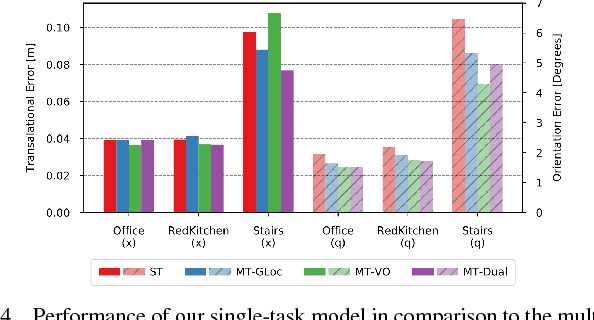
Localization is an indispensable component of a robot's autonomy stack that enables it to determine where it is in the environment, essentially making it a precursor for any action execution or planning. Although convolutional neural networks have shown promising results for visual localization, they are still grossly outperformed by state-of-the-art local feature-based techniques. In this work, we propose VLocNet, a new convolutional neural network architecture for 6-DoF global pose regression and odometry estimation from consecutive monocular images. Our multitask model incorporates hard parameter sharing, thus being compact and enabling real-time inference, in addition to being end-to-end trainable. We propose a novel loss function that utilizes auxiliary learning to leverage relative pose information during training, thereby constraining the search space to obtain consistent pose estimates. We evaluate our proposed VLocNet on indoor as well as outdoor datasets and show that even our single task model exceeds the performance of state-of-the-art deep architectures for global localization, while achieving competitive performance for visual odometry estimation. Furthermore, we present extensive experimental evaluations utilizing our proposed Geometric Consistency Loss that show the effectiveness of multitask learning and demonstrate that our model is the first deep learning technique to be on par with, and in some cases outperforms state-of-the-art SIFT-based approaches.