 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Adaptation from Modeling with Meta-Optimizers for Meta Learning
Paper and Code
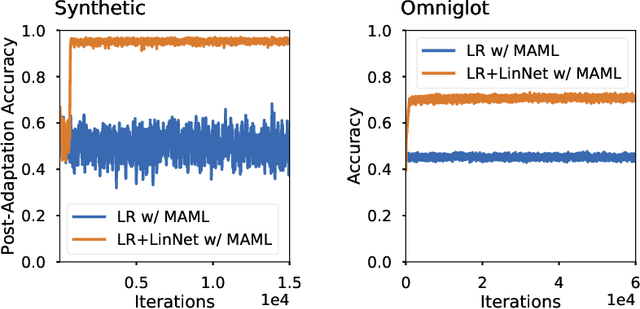

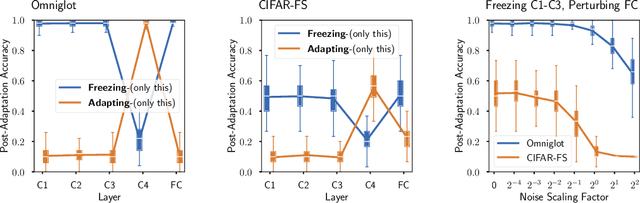

Meta-learning methods, most notably Model-Agnostic Meta-Learning or MAML, have achieved great success in adapting to new tasks quickly, after having been trained on similar tasks. The mechanism behind their success, however, is poorly understood. We begin this work with an experimental analysis of MAML, finding that deep models are crucial for its success, even given sets of simple tasks where a linear model would suffice on any individual task. Furthermore, on image-recognition tasks, we find that the early layers of MAML-trained models learn task-invariant features, while later layers are used for adaptation, providing further evidence that these models require greater capacity than is strictly necessary for their individual tasks. Following our findings, we propose a method which enables better use of model capacity at inference time by separating the adaptation aspect of meta-learning into parameters that are only used for adaptation but are not part of the forward model. We find that our approach enables more effective meta-learning in smaller models, which are suitably sized for the individual tasks.