 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeconstructing Distributions: A Pointwise Framework of Learning
Paper and Code
Feb 20, 2022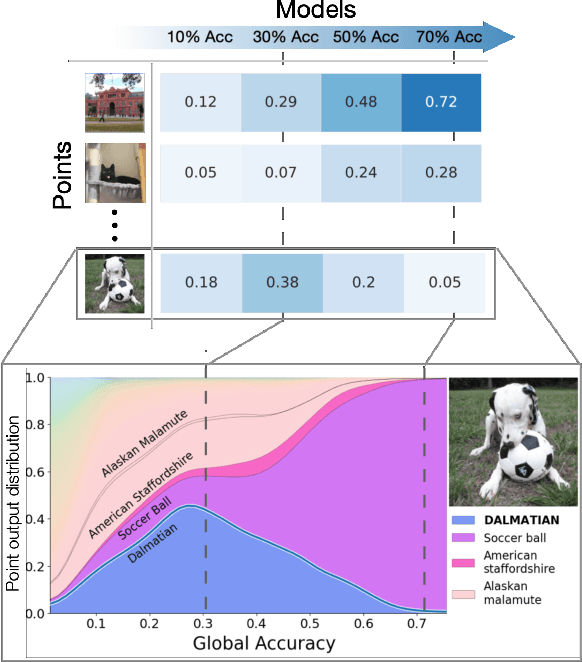

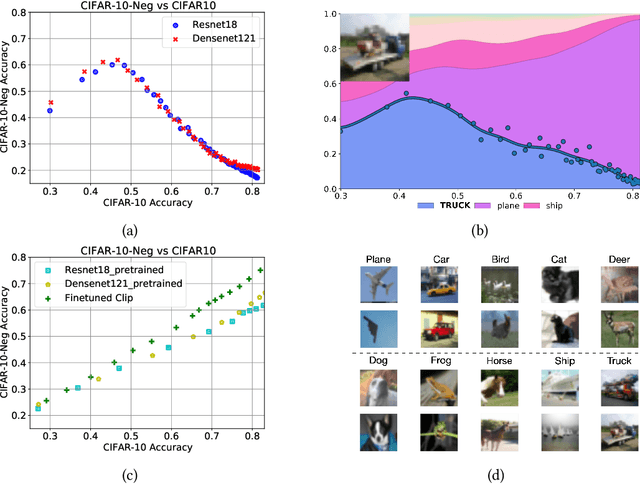

In machine learning, we traditionally evaluate the performance of a single model, averaged over a collection of test inputs. In this work, we propose a new approach: we measure the performance of a collection of models when evaluated on a $\textit{single input point}$. Specifically, we study a point's $\textit{profile}$: the relationship between models' average performance on the test distribution and their pointwise performance on this individual point. We find that profiles can yield new insights into the structure of both models and data -- in and out-of-distribution. For example, we empirically show that real data distributions consist of points with qualitatively different profiles. On one hand, there are "compatible" points with strong correlation between the pointwise and average performance. On the other hand, there are points with weak and even $\textit{negative}$ correlation: cases where improving overall model accuracy actually $\textit{hurts}$ performance on these inputs. We prove that these experimental observations are inconsistent with the predictions of several simplified models of learning proposed in prior work. As an application, we use profiles to construct a dataset we call CIFAR-10-NEG: a subset of CINIC-10 such that for standard models, accuracy on CIFAR-10-NEG is $\textit{negatively correlated}$ with accuracy on CIFAR-10 test. This illustrates, for the first time, an OOD dataset that completely inverts "accuracy-on-the-line" (Miller, Taori, Raghunathan, Sagawa, Koh, Shankar, Liang, Carmon, and Schmidt 2021)