 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposed Vector-Quantized Variational Autoencoder for Human Grasp Generation
Paper and Code


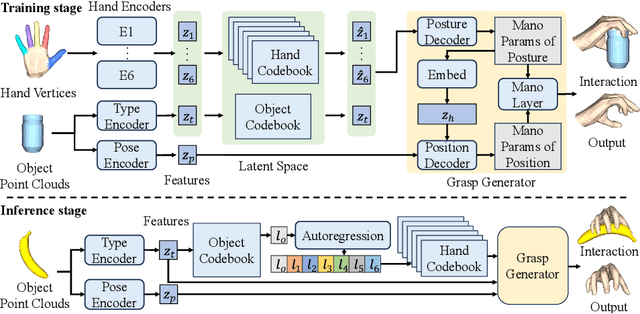

Generating realistic human grasps is a crucial yet challenging task for applications involving object manipulation in computer graphics and robotics. Existing methods often struggle with generating fine-grained realistic human grasps that ensure all fingers effectively interact with objects, as they focus on encoding hand with the whole representation and then estimating both hand posture and position in a single step. In this paper, we propose a novel Decomposed Vector-Quantized Variational Autoencoder (DVQ-VAE) to address this limitation by decomposing hand into several distinct parts and encoding them separately. This part-aware decomposed architecture facilitates more precise management of the interaction between each component of hand and object, enhancing the overall reality of generated human grasps. Furthermore, we design a newly dual-stage decoding strategy, by first determining the type of grasping under skeletal physical constraints, and then identifying the location of the grasp, which can greatly improve the verisimilitude as well as adaptability of the model to unseen hand-object interaction. In experiments, our model achieved about 14.1% relative improvement in the quality index compared to the state-of-the-art methods in four widely-adopted benchmarks. Our source code is available at https://github.com/florasion/D-VQVAE.