 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Visual Neural Representations by Multimodal Learning of Brain-Visual-Linguistic Features
Paper and Code
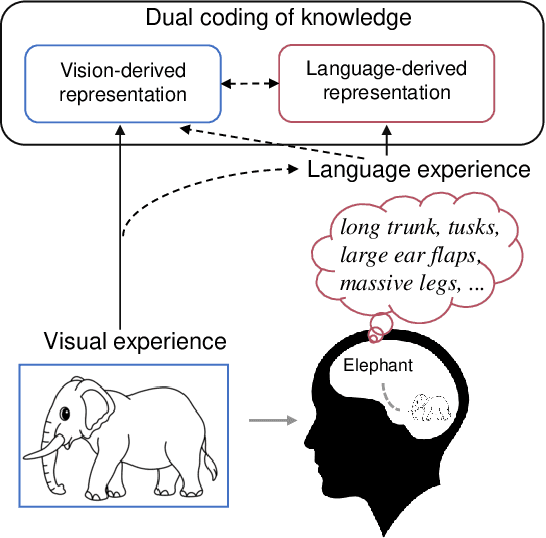


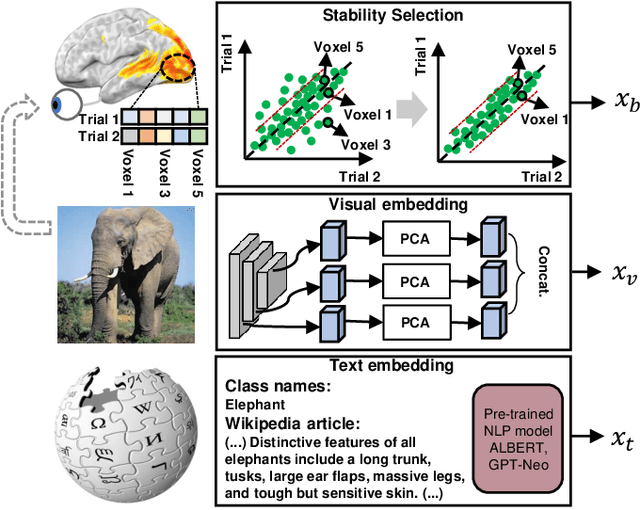
Decoding human visual neural representations is a challenging task with great scientific significance in revealing vision-processing mechanisms and developing brain-like intelligent machines. Most existing methods are difficult to generalize to novel categories that have no corresponding neural data for training. The two main reasons are 1) the under-exploitation of the multimodal semantic knowledge underlying the neural data and 2) the small number of paired (stimuli-responses) training data. To overcome these limitations, this paper presents a generic neural decoding method called BraVL that uses multimodal learning of brain-visual-linguistic features. We focus on modeling the relationships between brain, visual and linguistic features via multimodal deep generative models. Specifically, we leverage the mixture-of-product-of-experts formulation to infer a latent code that enables a coherent joint generation of all three modalities. To learn a more consistent joint representation and improve the data efficiency in the case of limited brain activity data, we exploit both intra- and inter-modality mutual information maximization regularization terms. In particular, our BraVL model can be trained under various semi-supervised scenarios to incorporate the visual and textual features obtained from the extra categories. Finally, we construct three trimodal matching datasets, and the extensive experiments lead to some interesting conclusions and cognitive insights: 1) decoding novel visual categories from human brain activity is practically possible with good accuracy; 2) decoding models using the combination of visual and linguistic features perform much better than those using either of them alone; 3) visual perception may be accompanied by linguistic influences to represent the semantics of visual stimuli. Code and data: https://github.com/ChangdeDu/BraVL.