 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Stochastic Gradient Tracking for Empirical Risk Minimization
Paper and Code
Sep 06, 2019

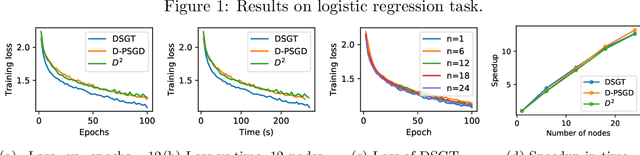
Recent works have shown superiorities of decentralized SGD to centralized counterparts in large-scale machine learning, but their theoretical gap is still not fully understood. In this paper, we propose a decentralized stochastic gradient tracking (DSGT) algorithm over peer-to-peer networks for empirical risk minimization problems, and explicitly evaluate its convergence rate in terms of key parameters of the problem, e.g., algebraic connectivity of the communication network, mini-batch size, and gradient variance. Importantly, it is the first theoretical result that can \emph{exactly} recover the rate of the centralized SGD, and has optimal dependence on the algebraic connectivity of the networks when using stochastic gradients. Moreover, we explicitly quantify how the network affects speedup and the rate improvement over existing works. Interestingly, we also point out for the first time that both linear and sublinear speedup can be possible. We empirically validate DSGT on neural networks and logistic regression problems, and show its advantage over the state-of-the-art algorithms.