 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecanus to Legatus: Synthetic training for 2D-3D human pose lifting
Paper and Code
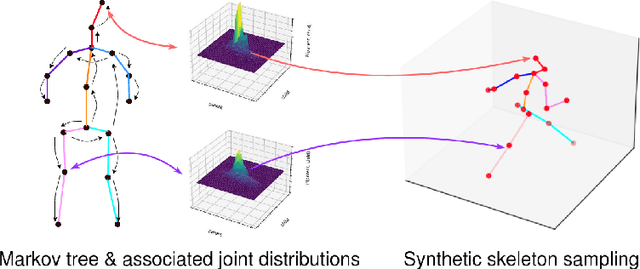



3D human pose estimation is a challenging task because of the difficulty to acquire ground-truth data outside of controlled environments. A number of further issues have been hindering progress in building a universal and robust model for this task, including domain gaps between different datasets, unseen actions between train and test datasets, various hardware settings and high cost of annotation, etc. In this paper, we propose an algorithm to generate infinite 3D synthetic human poses (Legatus) from a 3D pose distribution based on 10 initial handcrafted 3D poses (Decanus) during the training of a 2D to 3D human pose lifter neural network. Our results show that we can achieve 3D pose estimation performance comparable to methods using real data from specialized datasets but in a zero-shot setup, showing the generalization potential of our framework.