 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiasing In-Sample Policy Performance for Small-Data, Large-Scale Optimization
Paper and Code
Jul 28, 2021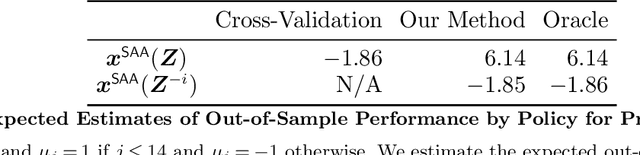
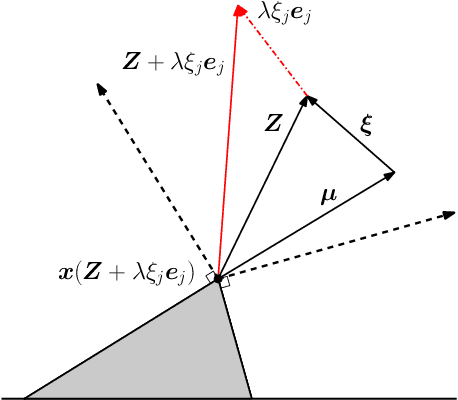
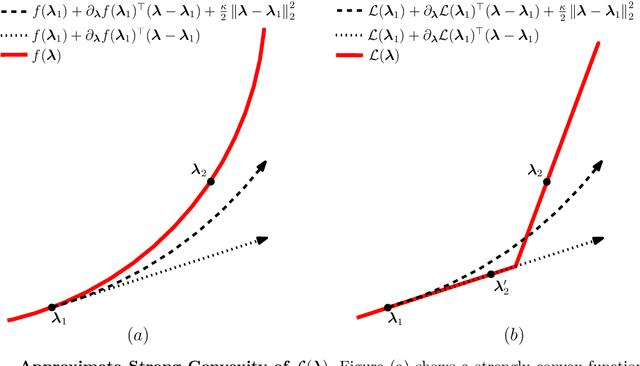
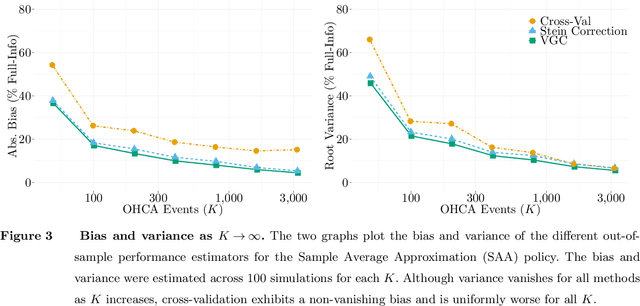
Motivated by the poor performance of cross-validation in settings where data are scarce, we propose a novel estimator of the out-of-sample performance of a policy in data-driven optimization.Our approach exploits the optimization problem's sensitivity analysis to estimate the gradient of the optimal objective value with respect to the amount of noise in the data and uses the estimated gradient to debias the policy's in-sample performance. Unlike cross-validation techniques, our approach avoids sacrificing data for a test set, utilizes all data when training and, hence, is well-suited to settings where data are scarce. We prove bounds on the bias and variance of our estimator for optimization problems with uncertain linear objectives but known, potentially non-convex, feasible regions. For more specialized optimization problems where the feasible region is "weakly-coupled" in a certain sense, we prove stronger results. Specifically, we provide explicit high-probability bounds on the error of our estimator that hold uniformly over a policy class and depends on the problem's dimension and policy class's complexity. Our bounds show that under mild conditions, the error of our estimator vanishes as the dimension of the optimization problem grows, even if the amount of available data remains small and constant. Said differently, we prove our estimator performs well in the small-data, large-scale regime. Finally, we numerically compare our proposed method to state-of-the-art approaches through a case-study on dispatching emergency medical response services using real data. Our method provides more accurate estimates of out-of-sample performance and learns better-performing policies.