Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDe-identification of Unstructured Clinical Texts from Sequence to Sequence Perspective
Paper and Code
Sep 10, 2021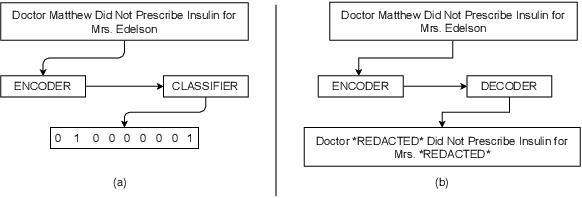
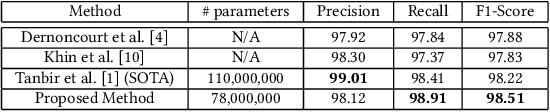
In this work, we propose a novel problem formulation for de-identification of unstructured clinical text. We formulate the de-identification problem as a sequence to sequence learning problem instead of a token classification problem. Our approach is inspired by the recent state-of -the-art performance of sequence to sequence learning models for named entity recognition. Early experimentation of our proposed approach achieved 98.91% recall rate on i2b2 dataset. This performance is comparable to current state-of-the-art models for unstructured clinical text de-identification.
* Accepted in Poster Track for ACM CCS 2021
View paper on