 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCIM-AVSR : Efficient Audio-Visual Speech Recognition via Dual Conformer Interaction Module
Paper and Code
Aug 31, 2024


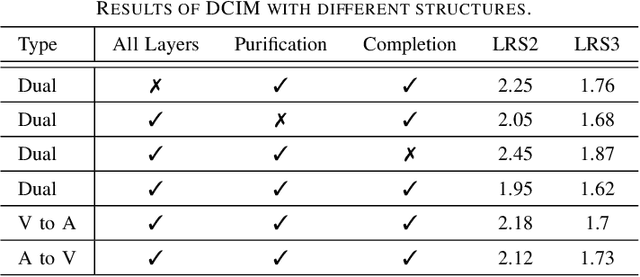
Speech recognition is the technology that enables machines to interpret and process human speech, converting spoken language into text or commands. This technology is essential for applications such as virtual assistants, transcription services, and communication tools. The Audio-Visual Speech Recognition (AVSR) model enhances traditional speech recognition, particularly in noisy environments, by incorporating visual modalities like lip movements and facial expressions. While traditional AVSR models trained on large-scale datasets with numerous parameters can achieve remarkable accuracy, often surpassing human performance, they also come with high training costs and deployment challenges. To address these issues, we introduce an efficient AVSR model that reduces the number of parameters through the integration of a Dual Conformer Interaction Module (DCIM). In addition, we propose a pre-training method that further optimizes model performance by selectively updating parameters, leading to significant improvements in efficiency. Unlike conventional models that require the system to independently learn the hierarchical relationship between audio and visual modalities, our approach incorporates this distinction directly into the model architecture. This design enhances both efficiency and performance, resulting in a more practical and effective solution for AVSR tasks.