 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Representation and Compression Using Linear-Programming Approximations
Paper and Code
May 03, 2016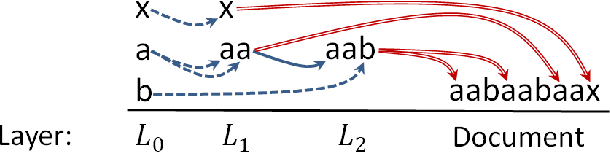
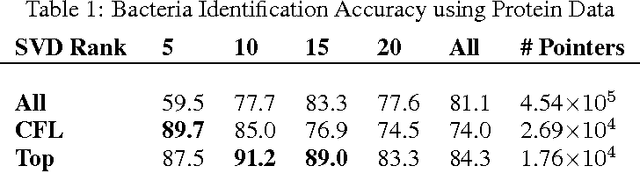
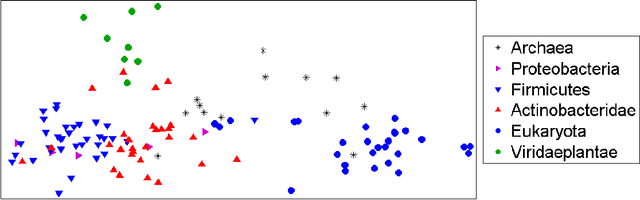
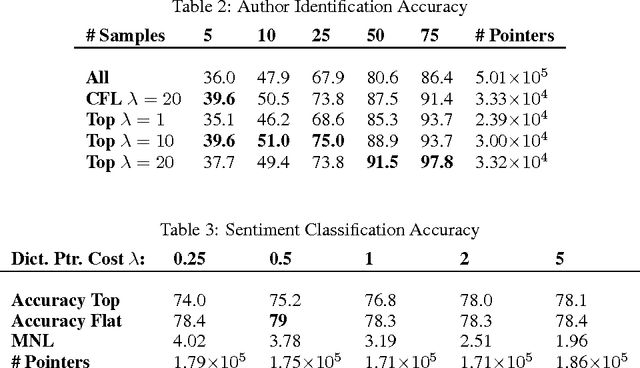
We propose `Dracula', a new framework for unsupervised feature selection from sequential data such as text. Dracula learns a dictionary of $n$-grams that efficiently compresses a given corpus and recursively compresses its own dictionary; in effect, Dracula is a `deep' extension of Compressive Feature Learning. It requires solving a binary linear program that may be relaxed to a linear program. Both problems exhibit considerable structure, their solution paths are well behaved, and we identify parameters which control the depth and diversity of the dictionary. We also discuss how to derive features from the compressed documents and show that while certain unregularized linear models are invariant to the structure of the compressed dictionary, this structure may be used to regularize learning. Experiments are presented that demonstrate the efficacy of Dracula's features.