 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData pruning and neural scaling laws: fundamental limitations of score-based algorithms
Paper and Code


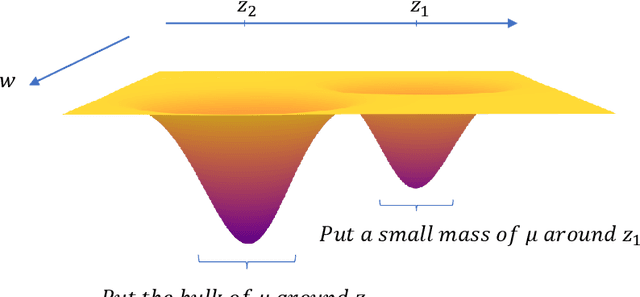

Data pruning algorithms are commonly used to reduce the memory and computational cost of the optimization process. Recent empirical results reveal that random data pruning remains a strong baseline and outperforms most existing data pruning methods in the high compression regime, i.e., where a fraction of $30\%$ or less of the data is kept. This regime has recently attracted a lot of interest as a result of the role of data pruning in improving the so-called neural scaling laws; in [Sorscher et al.], the authors showed the need for high-quality data pruning algorithms in order to beat the sample power law. In this work, we focus on score-based data pruning algorithms and show theoretically and empirically why such algorithms fail in the high compression regime. We demonstrate ``No Free Lunch" theorems for data pruning and present calibration protocols that enhance the performance of existing pruning algorithms in this high compression regime using randomization.