Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData movement limits to frontier model training
Paper and Code
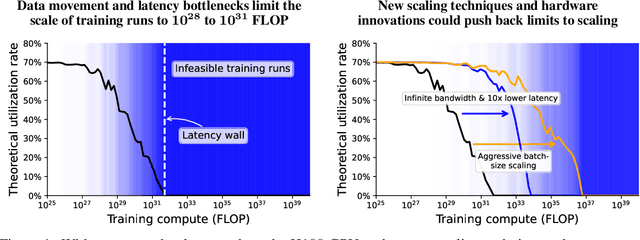

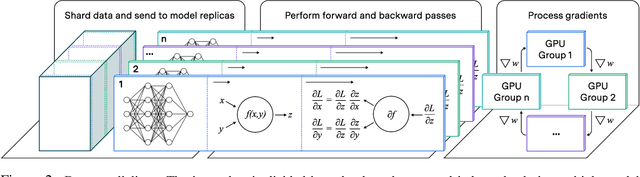

We present a theoretical model of distributed training, and use it to analyze how far dense and sparse training runs can be scaled. Under our baseline assumptions, given a three month training duration, data movement bottlenecks begin to significantly lower hardware utilization for training runs exceeding about $10^{28}$ FLOP, two orders of magnitude above the largest training run to date, \textbf{suggesting the arrival of fundamental barriers to scaling in three years} given recent rates of growth. A training run exceeding about $10^{31}$ FLOP is infeasible even at low utilization. However, more aggressive batch size scaling and/or shorter and fatter model shapes, if achievable, have the potential to permit much larger training runs.
View paper on