 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Efficient and Safe Learning for Locomotion via Simplified Model
Paper and Code
Jun 10, 2019

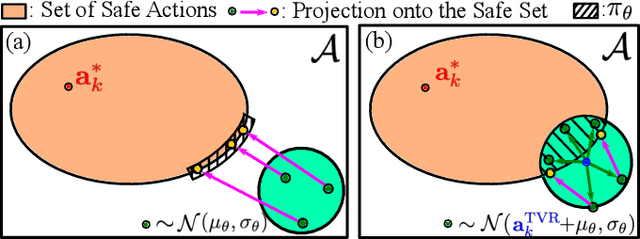
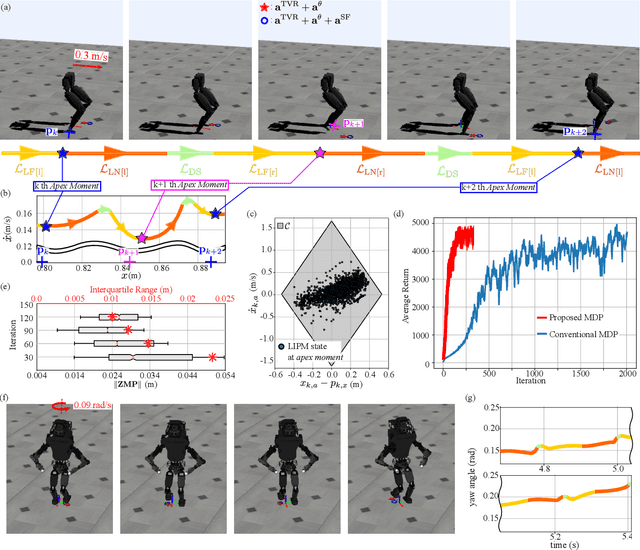
In this letter, we formulate a novel Markov Decision Process (MDP) for data efficient and safe learning for locomotion via a simplified model. In our previous studies on biped locomotion, we relied on a low-dimensional robot model, e.g., the Linear Inverted Pendulum Model (LIPM), commonly used in Walking Pattern Generators (WPG). However, employing low-level control cannot precisely track desired footstep locations due to the discrepancies between the real system and the simplified model. In this work, we propose an approach for mitigating this problem by complementing model-based policies with machine learning. We formulate an MDP process incorporating dynamic properties of robots, desired walking directions, and footstep features. We iteratively update the policy to determine footstep locations based on the previous MDP process aided by a deep reinforcement learning process. The policy of the proposed approach consists of a WPG and a parameterized stochastic policy. In addition, a Control Barrier Function (CBF) process applies corrections the above policy to prevent exploration of unsafe regions during learning. Our contributions include: 1) reduction of footstep tracking errors resulting from employing LIPM; 2) efficient exploration of the data driven process, and; 3) scalability of the procedure to any humanoid robot.