 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven effective model shows a liquid-like deep learning
Paper and Code
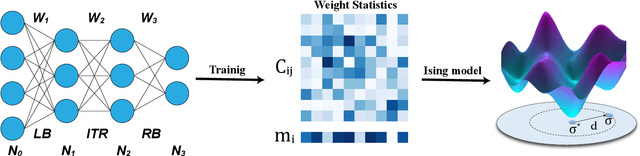
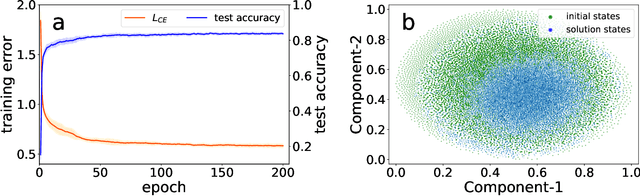
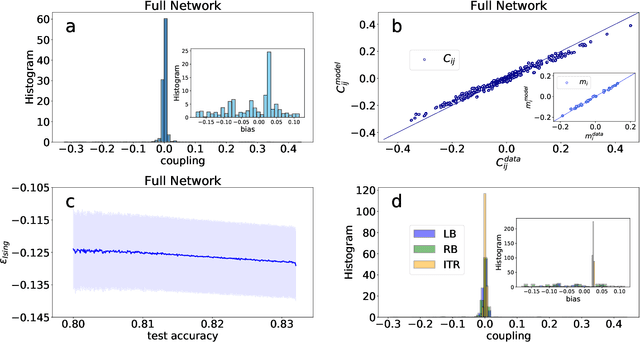
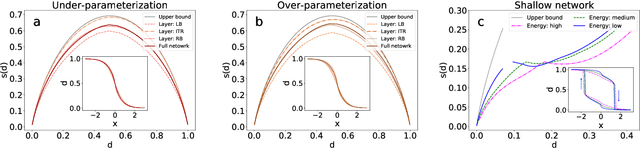
Geometric structure of an optimization landscape is argued to be fundamentally important to support the success of deep learning. However, recent research efforts focused on either of toy random models with unrealistic assumptions and numerical evidences about different shapes of the optimization landscape, thereby lacking a unified view about the nature of the landscape. Here, we propose a statistical mechanics framework by directly building a least structured model of the high-dimensional weight space, considering realistic structured data, stochastic gradient descent algorithms, and the computational depth of the network parametrized by weight parameters. We also consider whether the number of network parameters outnumbers the number of supplied training data, namely, over- or under-parametrization. Our least structured model predicts that the weight spaces of the under-parametrization and over-parameterization cases belong to the same class. These weight spaces are well-connected without any heterogeneous geometric properties. In contrast, the shallow-network has a shattered weight space, characterized by discontinuous phase transitions in physics, thereby clarifying roles of depth in deep learning. Our effective model also predicts that inside a deep network, there exists a liquid-like central part of the architecture in the sense that the weights in this part behave as randomly as possible. Our work may thus explain why deep learning is unreasonably effective in terms of the high-dimensional weight space, and how deep networks are different from shallow ones.