 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation with norm-VAE for Unsupervised Domain Adaptation
Paper and Code
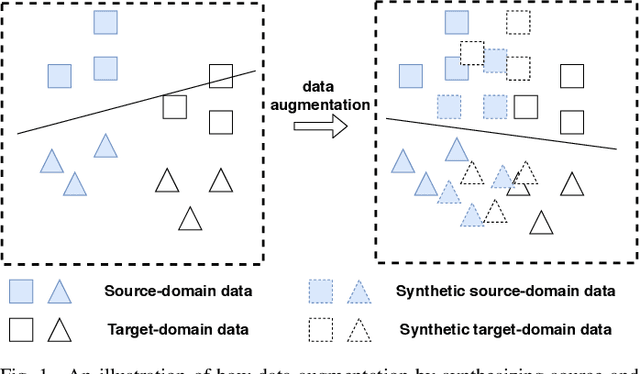
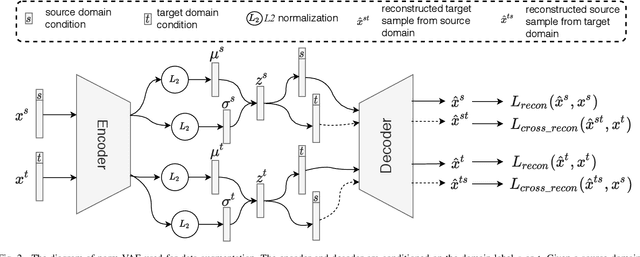


We address the Unsupervised Domain Adaptation (UDA) problem in image classification from a new perspective. In contrast to most existing works which either align the data distributions or learn domain-invariant features, we directly learn a unified classifier for both domains within a high-dimensional homogeneous feature space without explicit domain adaptation. To this end, we employ the effective Selective Pseudo-Labelling (SPL) techniques to take advantage of the unlabelled samples in the target domain. Surprisingly, data distribution discrepancy across the source and target domains can be well handled by a computationally simple classifier (e.g., a shallow Multi-Layer Perceptron) trained in the original feature space. Besides, we propose a novel generative model norm-VAE to generate synthetic features for the target domain as a data augmentation strategy to enhance classifier training. Experimental results on several benchmark datasets demonstrate the pseudo-labelling strategy itself can lead to comparable performance to many state-of-the-art methods whilst the use of norm-VAE for feature augmentation can further improve the performance in most cases. As a result, our proposed methods (i.e. naive-SPL and norm-VAE-SPL) can achieve new state-of-the-art performance with the average accuracy of 93.4% and 90.4% on Office-Caltech and ImageCLEF-DA datasets, and comparable performance on Digits, Office31 and Office-Home datasets with the average accuracy of 97.2%, 87.6% and 67.9% respectively.