Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAPAS : Denoising Autoencoder to Prevent Adversarial attack in Semantic Segmentation
Paper and Code
Aug 18, 2019

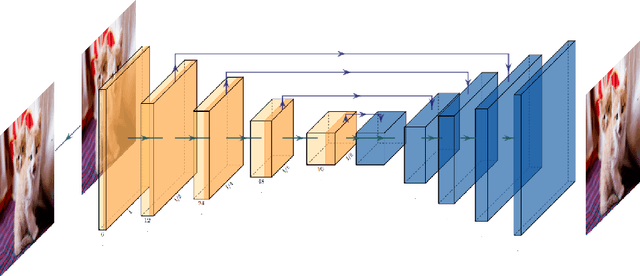

Nowadays, Deep learning techniques show dramatic performance on computer vision area, and they even outperform human. But it is also vulnerable to some small perturbation called an adversarial attack. This is a problem combined with the safety of artificial intelligence, which has recently been studied a lot. These attacks have shown that they can fool models of image classification, semantic segmentation, and object detection. We point out this attack can be protected by denoise autoencoder, which is used for denoising the perturbation and restoring the original images. We experiment with various noise distributions and verify the effect of denoise autoencoder against adversarial attack in semantic segmentation.
* 8 pages, 8 figures
View paper on