 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDALG: Deep Attentive Local and Global Modeling for Image Retrieval
Paper and Code
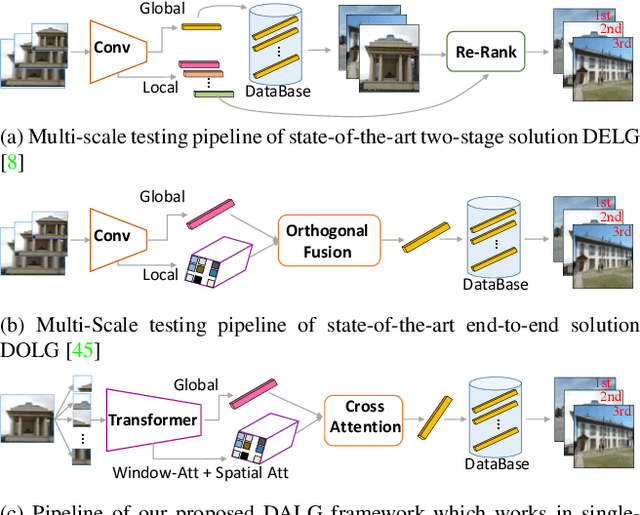
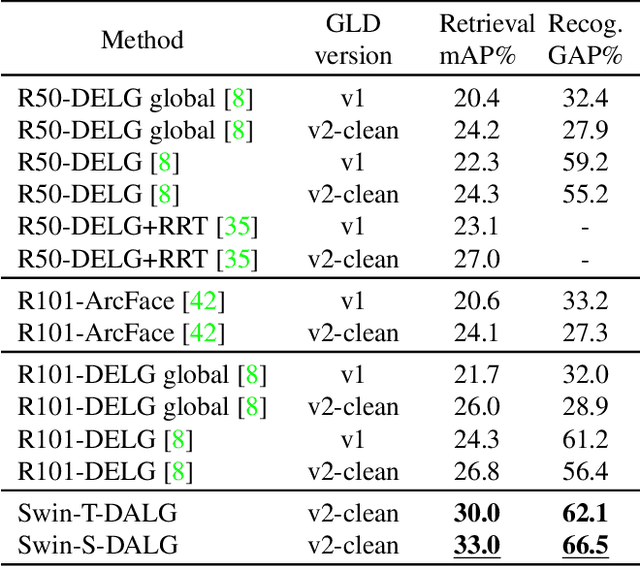


Deeply learned representations have achieved superior image retrieval performance in a retrieve-then-rerank manner. Recent state-of-the-art single stage model, which heuristically fuses local and global features, achieves promising trade-off between efficiency and effectiveness. However, we notice that efficiency of existing solutions is still restricted because of their multi-scale inference paradigm. In this paper, we follow the single stage art and obtain further complexity-effectiveness balance by successfully getting rid of multi-scale testing. To achieve this goal, we abandon the widely-used convolution network giving its limitation in exploring diverse visual patterns, and resort to fully attention based framework for robust representation learning motivated by the success of Transformer. Besides applying Transformer for global feature extraction, we devise a local branch composed of window-based multi-head attention and spatial attention to fully exploit local image patterns. Furthermore, we propose to combine the hierarchical local and global features via a cross-attention module, instead of using heuristically fusion as previous art does. With our Deep Attentive Local and Global modeling framework (DALG), extensive experimental results show that efficiency can be significantly improved while maintaining competitive results with the state of the arts.