 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDA2: Deep Attention Adapter for Memory-EfficientOn-Device Multi-Domain Learning
Paper and Code
Dec 02, 2020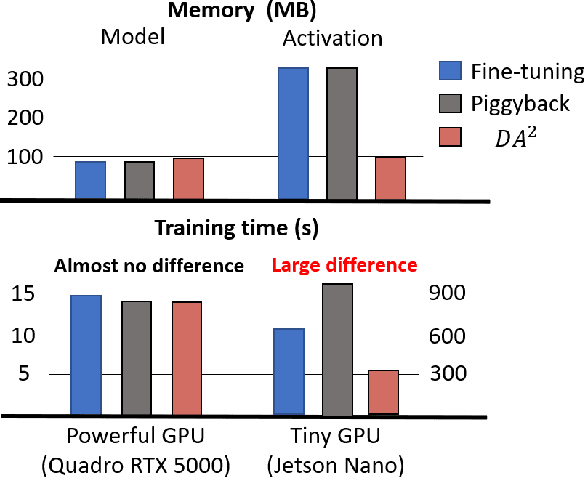


Nowadays, one practical limitation of deep neural network (DNN) is its high degree of specialization to a single task or domain (e.g. one visual domain). It motivates researchers to develop algorithms that can adapt DNN model to multiple domains sequentially, meanwhile still performing well on the past domains, which is known as multi-domain learning. Conventional methods only focus on improving accuracy with minimal parameter update, while ignoring high computing and memory usage during training, which makes it impossible to deploy into more and more widely used resource-limited edge devices, like mobile phone, IoT, embedded systems, etc. During our study, we observe that memory used for activation storage is the bottleneck that largely limits the training time and cost on edge devices. To reduce training memory usage, while keeping the domain adaption accuracy performance, in this work, we propose Deep Attention Adaptor, a novel on-device multi-domain learning method, aiming to achieve domain adaption on resource-limited edge devices in both fast and memory-efficient manner. During on-device training, DA2 freezes the weights of pre-trained backbone model to reduce the training memory consumption (i.e., no need to store activation features during backward propagation). Furthermore, to improve the adaption accuracy performance, we propose to improve the model capacity by learning a light-weight memory-efficient residual attention adaptor module. We validate DA2 on multiple datasets against state-of-the-art methods, which shows good improvement in both accuracy and training cost. Finally, we demonstrate the algorithm's efficiency on NIVDIA Jetson Nano tiny GPU, proving the proposed DA2 reduces the on-device memory consumption by 19-37x during training in comparison to the baseline methods.