Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCzech Text Processing with Contextual Embeddings: POS Tagging, Lemmatization, Parsing and NER
Paper and Code


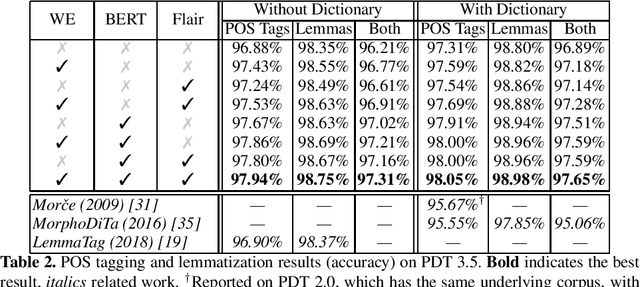
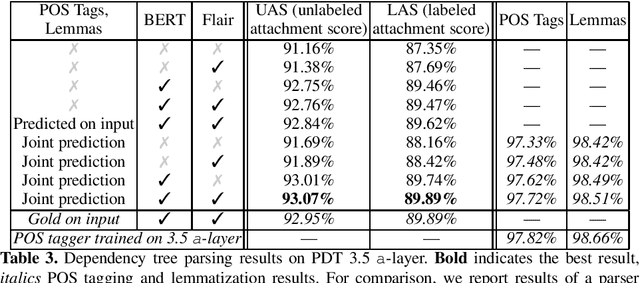
Contextualized embeddings, which capture appropriate word meaning depending on context, have recently been proposed. We evaluate two meth ods for precomputing such embeddings, BERT and Flair, on four Czech text processing tasks: part-of-speech (POS) tagging, lemmatization, dependency pars ing and named entity recognition (NER). The first three tasks, POS tagging, lemmatization and dependency parsing, are evaluated on two corpora: the Prague Dependency Treebank 3.5 and the Universal Dependencies 2.3. The named entity recognition (NER) is evaluated on the Czech Named Entity Corpus 1.1 and 2.0. We report state-of-the-art results for the above mentioned tasks and corpora.
View paper on