 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum Learning for Data-Efficient Vision-Language Alignment
Paper and Code
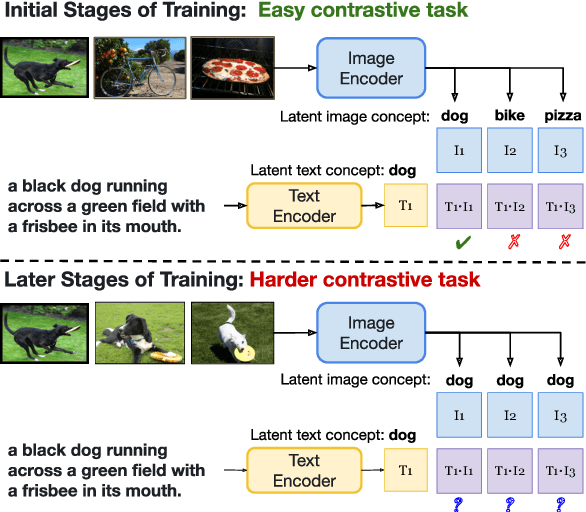
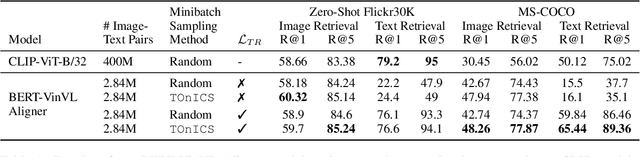
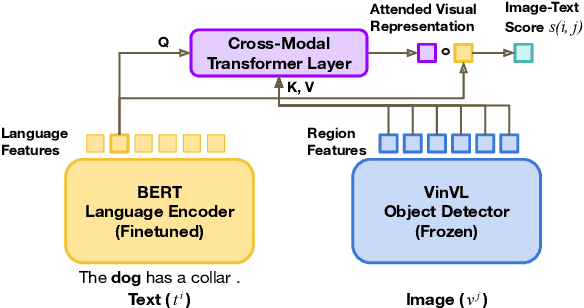
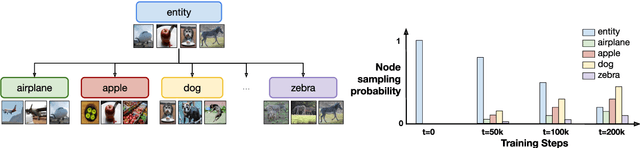
Aligning image and text encoders from scratch using contrastive learning requires large amounts of paired image-text data. We alleviate this need by aligning individually pre-trained language and vision representation models using a much smaller amount of paired data, augmented with a curriculum learning algorithm to learn fine-grained vision-language alignments. TOnICS (Training with Ontology-Informed Contrastive Sampling) initially samples minibatches whose image-text pairs contain a wide variety of objects to learn object-level alignment, and progressively samples minibatches where all image-text pairs contain the same object to learn finer-grained contextual alignment. Aligning pre-trained BERT and VinVL models to each other using TOnICS outperforms CLIP on downstream zero-shot image retrieval while using less than 1% as much training data.