Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurating Subject ID Labels using Keypoint Signatures
Paper and Code
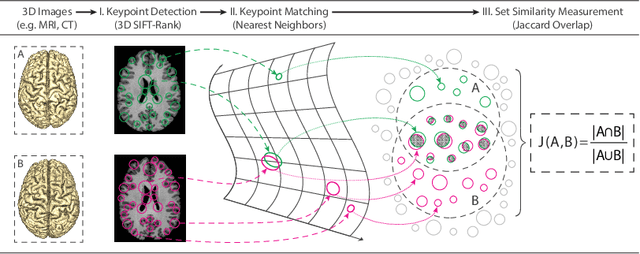

Subject ID labels are unique, anonymized codes that can be used to group all images of a subject while maintaining anonymity. ID errors may be inadvertently introduced manually error during enrollment and may lead to systematic error into machine learning evaluation (e.g. due to double-dipping) or potential patient misdiagnosis in clinical contexts. Here we describe a highly efficient system for curating subject ID labels in large generic medical image datasets, based on the 3D image keypoint representation, which recently led to the discovery of previously unknown labeling errors in widely-used public brain MRI datasets
View paper on