 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTC-GMM: CTC guided modality matching for fast and accurate streaming speech translation
Paper and Code
Oct 07, 2024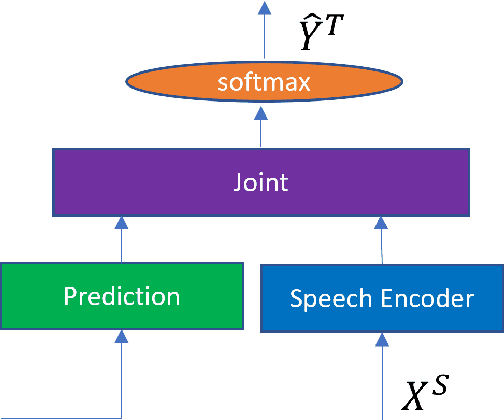
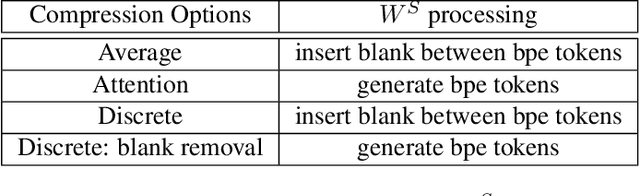
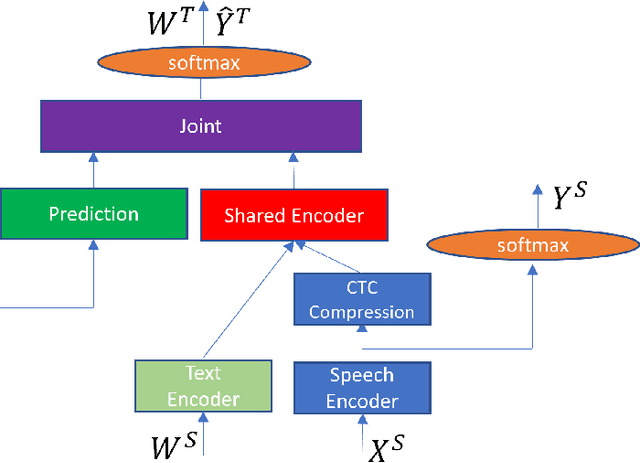
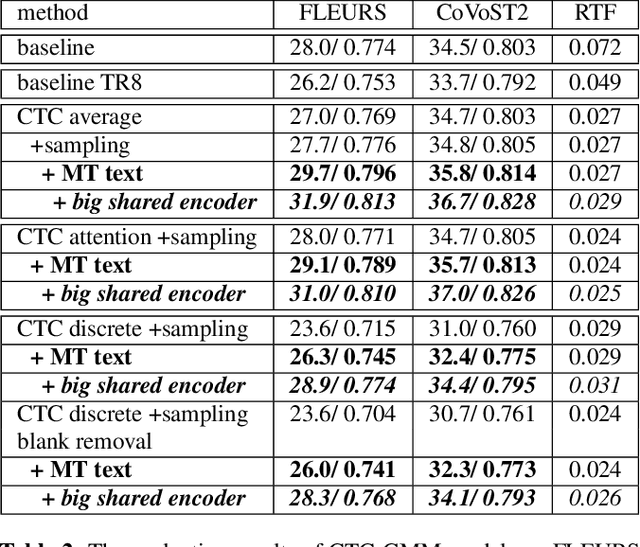
Models for streaming speech translation (ST) can achieve high accuracy and low latency if they're developed with vast amounts of paired audio in the source language and written text in the target language. Yet, these text labels for the target language are often pseudo labels due to the prohibitive cost of manual ST data labeling. In this paper, we introduce a methodology named Connectionist Temporal Classification guided modality matching (CTC-GMM) that enhances the streaming ST model by leveraging extensive machine translation (MT) text data. This technique employs CTC to compress the speech sequence into a compact embedding sequence that matches the corresponding text sequence, allowing us to utilize matched {source-target} language text pairs from the MT corpora to refine the streaming ST model further. Our evaluations with FLEURS and CoVoST2 show that the CTC-GMM approach can increase translation accuracy relatively by 13.9% and 6.4% respectively, while also boosting decoding speed by 59.7% on GPU.