 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossFuse: A Novel Cross Attention Mechanism based Infrared and Visible Image Fusion Approach
Paper and Code



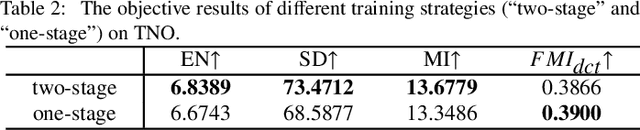
Multimodal visual information fusion aims to integrate the multi-sensor data into a single image which contains more complementary information and less redundant features. However the complementary information is hard to extract, especially for infrared and visible images which contain big similarity gap between these two modalities. The common cross attention modules only consider the correlation, on the contrary, image fusion tasks need focus on complementarity (uncorrelation). Hence, in this paper, a novel cross attention mechanism (CAM) is proposed to enhance the complementary information. Furthermore, a two-stage training strategy based fusion scheme is presented to generate the fused images. For the first stage, two auto-encoder networks with same architecture are trained for each modality. Then, with the fixed encoders, the CAM and a decoder are trained in the second stage. With the trained CAM, features extracted from two modalities are integrated into one fused feature in which the complementary information is enhanced and the redundant features are reduced. Finally, the fused image can be generated by the trained decoder. The experimental results illustrate that our proposed fusion method obtains the SOTA fusion performance compared with the existing fusion networks. The codes are available at https://github.com/hli1221/CrossFuse