 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Interaction Networks for Query-Based Moment Retrieval in Videos
Paper and Code

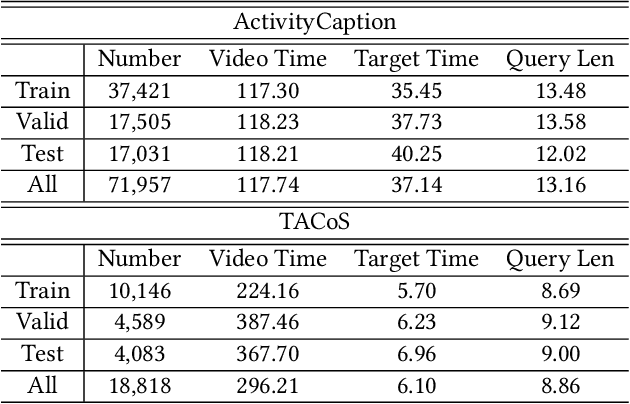
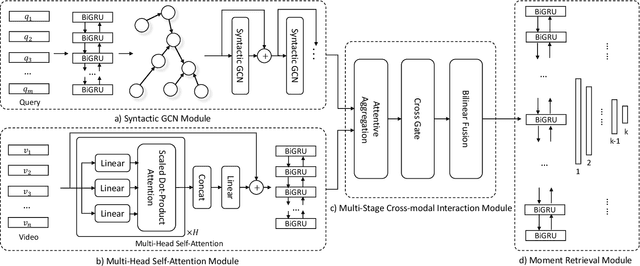
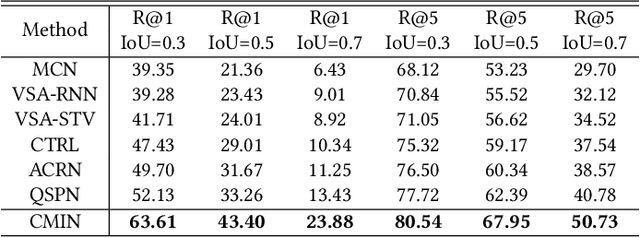
Query-based moment retrieval aims to localize the most relevant moment in an untrimmed video according to the given natural language query. Existing works often only focus on one aspect of this emerging task, such as the query representation learning, video context modeling or multi-modal fusion, thus fail to develop a comprehensive system for further performance improvement. In this paper, we introduce a novel Cross-Modal Interaction Network (CMIN) to consider multiple crucial factors for this challenging task, including (1) the syntactic structure of natural language queries; (2) long-range semantic dependencies in video context and (3) the sufficient cross-modal interaction. Specifically, we devise a syntactic GCN to leverage the syntactic structure of queries for fine-grained representation learning, propose a multi-head self-attention to capture long-range semantic dependencies from video context, and next employ a multi-stage cross-modal interaction to explore the potential relations of video and query contents. The extensive experiments demonstrate the effectiveness of our proposed method.