 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual alignments of ELMo contextual embeddings
Paper and Code
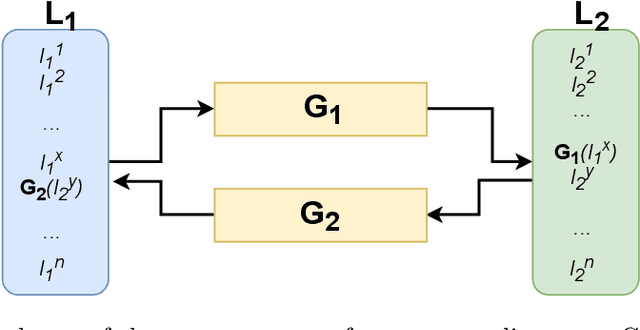
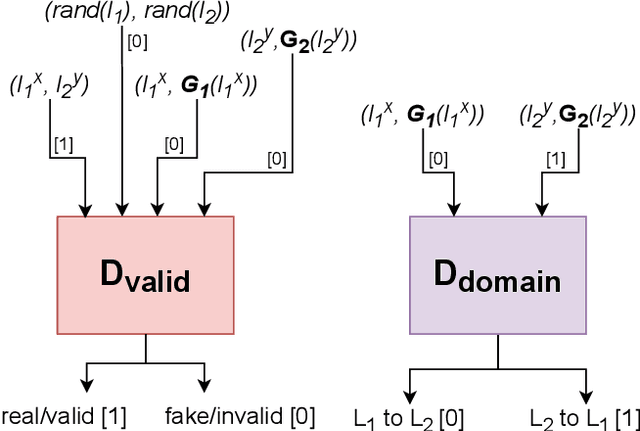
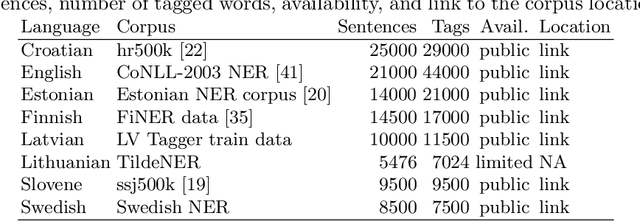
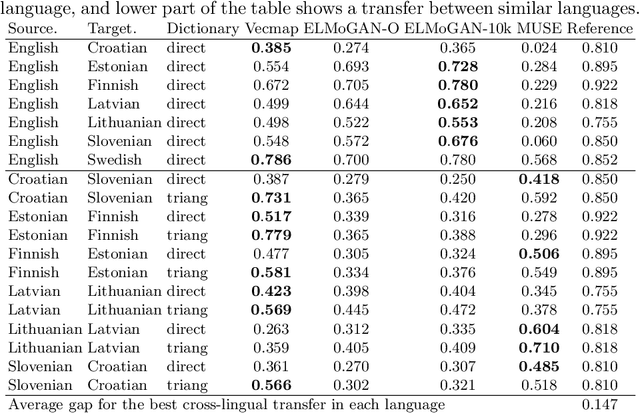
Building machine learning prediction models for a specific NLP task requires sufficient training data, which can be difficult to obtain for less-resourced languages. Cross-lingual embeddings map word embeddings from a less-resourced language to a resource-rich language so that a prediction model trained on data from the resource-rich language can also be used in the less-resourced language. To produce cross-lingual mappings of recent contextual embeddings, anchor points between the embedding spaces have to be words in the same context. We address this issue with a novel method for creating cross-lingual contextual alignment datasets. Based on that, we propose several cross-lingual mapping methods for ELMo embeddings. The proposed linear mapping methods use existing Vecmap and MUSE alignments on contextual ELMo embeddings. Novel nonlinear ELMoGAN mapping methods are based on GANs and do not assume isomorphic embedding spaces. We evaluate the proposed mapping methods on nine languages, using four downstream tasks: named entity recognition (NER), dependency parsing (DP), terminology alignment, and sentiment analysis. The ELMoGAN methods perform very well on the NER and terminology alignment tasks, with a lower cross-lingual loss for NER compared to the direct training on some languages. In DP and sentiment analysis, linear contextual alignment variants are more successful.