 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross Domain Imitation Learning
Paper and Code
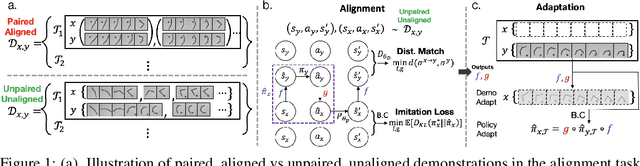

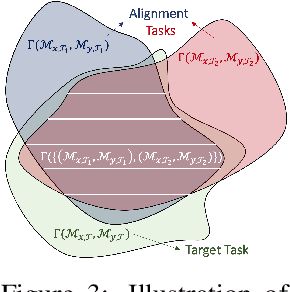

We study the question of how to imitate tasks across domains with discrepancies such as embodiment and viewpoint mismatch. Many prior works require paired, aligned demonstrations and an additional RL procedure for the task. However, paired, aligned demonstrations are seldom obtainable and RL procedures are expensive. In this work, we formalize the Cross Domain Imitation Learning (CDIL) problem, which encompasses imitation learning in the presence of viewpoint and embodiment mismatch. Informally, CDIL is the process of learning how to perform a task optimally, given demonstrations of the task in a distinct domain. We propose a two step approach to CDIL: alignment followed by adaptation. In the alignment step we execute a novel unsupervised MDP alignment algorithm, Generative Adversarial MDP Alignment (GAMA), to learn state and action correspondences from unpaired, unaligned demonstrations. In the adaptation step we leverage the correspondences to zero-shot imitate tasks across domains. To describe when CDIL is feasible via alignment and adaptation, we introduce a theory of MDP alignability. We experimentally evaluate GAMA against baselines in both embodiment and viewpoint mismatch scenarios where aligned demonstrations don't exist and show the effectiveness of our approach.