 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Generalization and Knowledge Transfer in Transformers Trained on Legal Data
Paper and Code
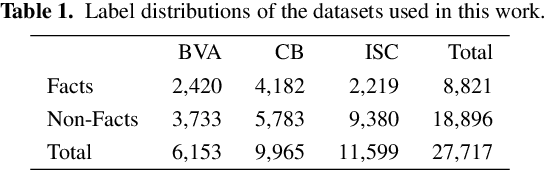

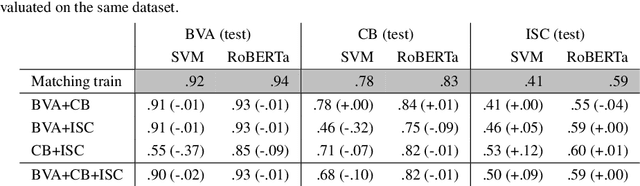
We analyze the ability of pre-trained language models to transfer knowledge among datasets annotated with different type systems and to generalize beyond the domain and dataset they were trained on. We create a meta task, over multiple datasets focused on the prediction of rhetorical roles. Prediction of the rhetorical role a sentence plays in a case decision is an important and often studied task in AI & Law. Typically, it requires the annotation of a large number of sentences to train a model, which can be time-consuming and expensive. Further, the application of the models is restrained to the same dataset it was trained on. We fine-tune language models and evaluate their performance across datasets, to investigate the models' ability to generalize across domains. Our results suggest that the approach could be helpful in overcoming the cold-start problem in active or interactvie learning, and shows the ability of the models to generalize across datasets and domains.