 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Document Event Coreference Resolution Beyond Corpus-Tailored Systems
Paper and Code


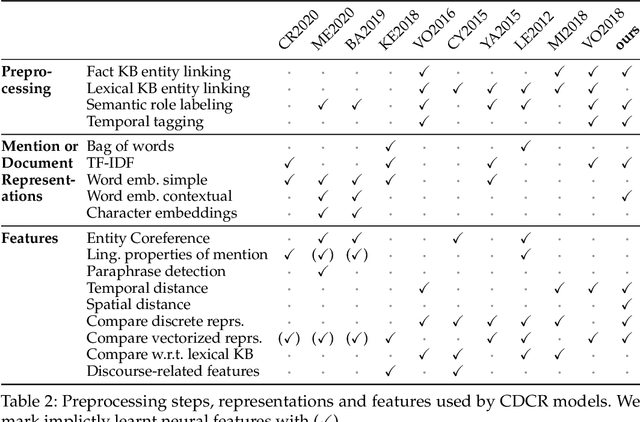
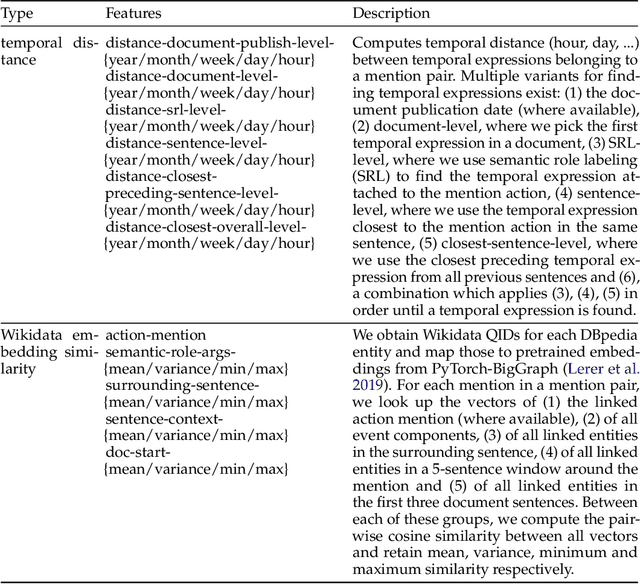
Cross-document event coreference resolution (CDCR) is an NLP task in which mentions of events need to be identified and clustered throughout a collection of documents. CDCR aims to benefit downstream multi-document applications, but despite recent progress on corpora and model development, downstream improvements from applying CDCR have not been shown yet. The reason lies in the fact that every CDCR system released to date was developed, trained, and tested only on a single respective corpus. This raises strong concerns on their generalizability --- a must-have for downstream applications where the magnitude of domains or event mentions is likely to exceed those found in a curated corpus. To approach this issue, we define a uniform evaluation setup involving three CDCR corpora: ECB+, the Gun Violence Corpus and the Football Coreference Corpus (which we reannotate on token level to make our analysis possible). We compare a corpus-independent, feature-based system against a recent neural system developed for ECB+. Whilst being inferior in absolute numbers, the feature-based system shows more consistent performance across all corpora whereas the neural system is hit-and-miss. Via model introspection, we find that the importance of event actions, event time, etc. for resolving coreference in practice varies greatly between the corpora. Additional analysis shows that several systems overfit on the structure of the ECB+ corpus. We conclude with recommendations on how to move beyond corpus-tailored CDCR systems in the future -- the most important being that evaluation on multiple CDCR corpora is strongly necessary. To facilitate future research, we release our dataset, annotation guidelines, and model implementation to the public.