 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCritic-Guided Decision Transformer for Offline Reinforcement Learning
Paper and Code
Dec 21, 2023
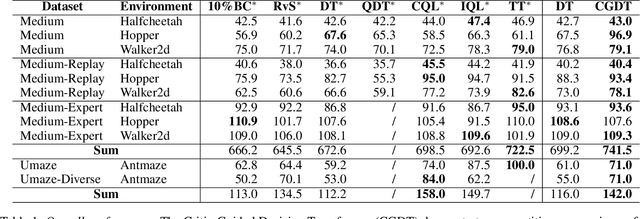

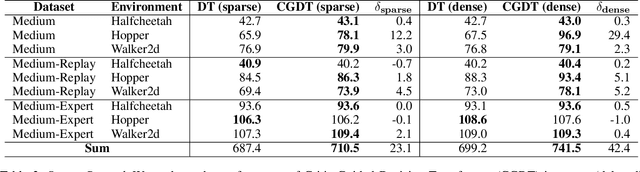
Recent advancements in offline reinforcement learning (RL) have underscored the capabilities of Return-Conditioned Supervised Learning (RCSL), a paradigm that learns the action distribution based on target returns for each state in a supervised manner. However, prevailing RCSL methods largely focus on deterministic trajectory modeling, disregarding stochastic state transitions and the diversity of future trajectory distributions. A fundamental challenge arises from the inconsistency between the sampled returns within individual trajectories and the expected returns across multiple trajectories. Fortunately, value-based methods offer a solution by leveraging a value function to approximate the expected returns, thereby addressing the inconsistency effectively. Building upon these insights, we propose a novel approach, termed the Critic-Guided Decision Transformer (CGDT), which combines the predictability of long-term returns from value-based methods with the trajectory modeling capability of the Decision Transformer. By incorporating a learned value function, known as the critic, CGDT ensures a direct alignment between the specified target returns and the expected returns of actions. This integration bridges the gap between the deterministic nature of RCSL and the probabilistic characteristics of value-based methods. Empirical evaluations on stochastic environments and D4RL benchmark datasets demonstrate the superiority of CGDT over traditional RCSL methods. These results highlight the potential of CGDT to advance the state of the art in offline RL and extend the applicability of RCSL to a wide range of RL tasks.