 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPET: Effective Parameter-Efficient Tuning for Compressed Large Language Models
Paper and Code
Jul 15, 2023


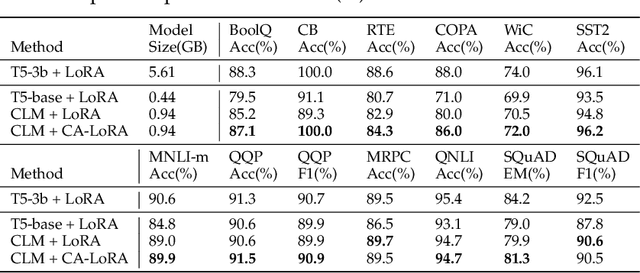
Parameter-efficient tuning (PET) has been widely explored in recent years because it tunes much fewer parameters (PET modules) than full-parameter fine-tuning (FT) while still stimulating sufficient knowledge from large language models (LLMs) for downstream tasks. Moreover, when PET is employed to serve multiple tasks, different task-specific PET modules can be built on a frozen LLM, avoiding redundant LLM deployments. Although PET significantly reduces the cost of tuning and deploying LLMs, its inference still suffers from the computational bottleneck of LLMs. To address the above issue, we propose an effective PET framework based on compressed LLMs, named "CPET". In CPET, we evaluate the impact of mainstream LLM compression techniques on PET performance and then introduce knowledge inheritance and recovery strategies to restore the knowledge loss caused by these compression techniques. Our experimental results demonstrate that, owing to the restoring strategies of CPET, collaborating task-specific PET modules with a compressed LLM can achieve comparable performance to collaborating PET modules with the original version of the compressed LLM and outperform directly applying vanilla PET methods to the compressed LLM.