 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactually Guided Policy Transfer in Clinical Settings
Paper and Code
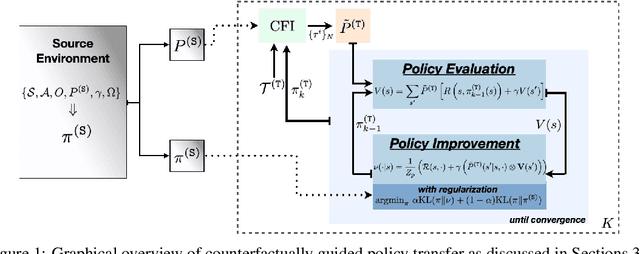

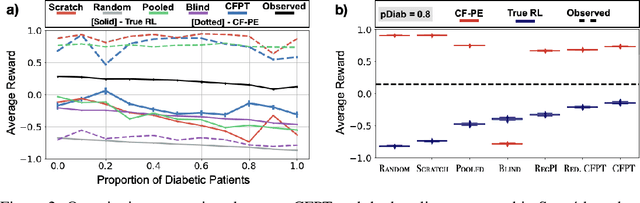
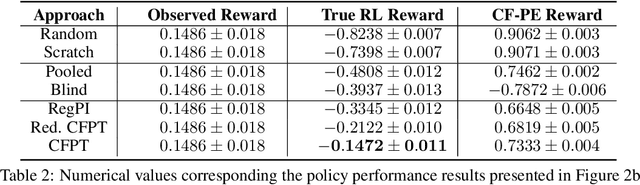
Reliably transferring treatment policies learned in one clinical environment to another is currently limited by challenges related to domain shift. In this paper we address off-policy learning for sequential decision making under domain shift -- a scenario susceptible to catastrophic overconfidence -- which is highly relevant to a high-stakes clinical settings where the target domain may also be data-scarce. We propose a two-fold counterfactual regularization procedure to improve off-policy learning, addressing domain shift and data scarcity. First, we utilize an informative prior derived from a data-rich source environment to indirectly improve drawing counterfactual example observations. Then, these samples are then used to learn a policy for the target domain, regularized by the source policy through KL-divergence. In simulated sepsis treatment, our counterfactual policy transfer procedure significantly improves the performance of a learned treatment policy.