 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORWA: A Citation-Oriented Related Work Annotation Dataset
Paper and Code


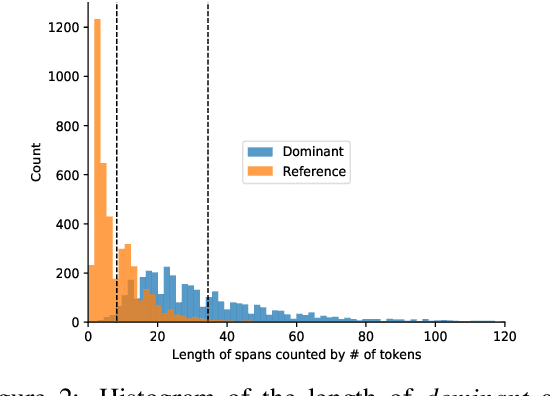
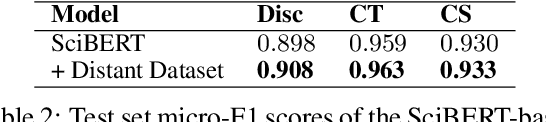
Academic research is an exploratory activity to discover new solutions to problems. By this nature, academic research works perform literature reviews to distinguish their novelties from prior work. In natural language processing, this literature review is usually conducted under the "Related Work" section. The task of related work generation aims to automatically generate the related work section given the rest of the research paper and a list of papers to cite. Prior work on this task has focused on the sentence as the basic unit of generation, neglecting the fact that related work sections consist of variable length text fragments derived from different information sources. As a first step toward a linguistically-motivated related work generation framework, we present a Citation Oriented Related Work Annotation (CORWA) dataset that labels different types of citation text fragments from different information sources. We train a strong baseline model that automatically tags the CORWA labels on massive unlabeled related work section texts. We further suggest a novel framework for human-in-the-loop, iterative, abstractive related work generation.