 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCopula-based synthetic data generation for machine learning emulators in weather and climate: application to a simple radiation model
Paper and Code
Jan 05, 2021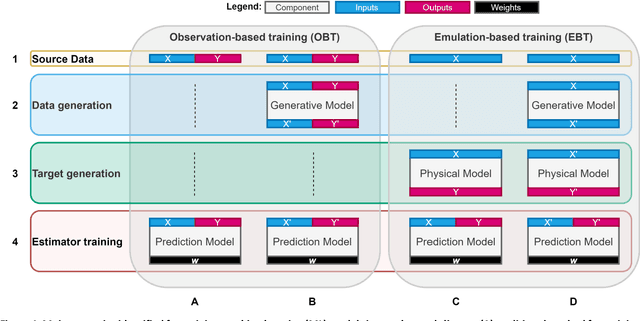

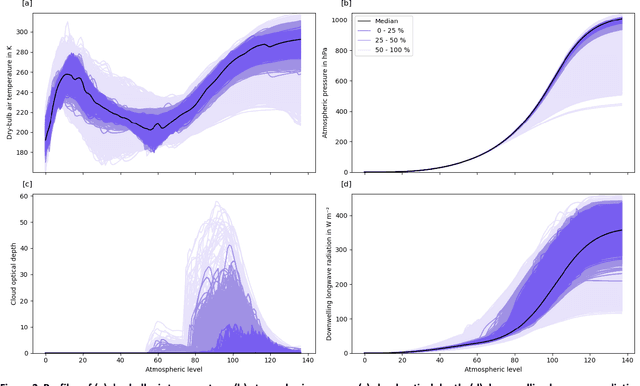

Can we improve machine learning (ML) emulators with synthetic data? The use of real data for training ML models is often the cause of major limitations. For example, real data may be (a) only representative of a subset of situations and domains, (b) expensive to source, (c) limited to specific individuals due to licensing restrictions. Although the use of synthetic data is becoming increasingly popular in computer vision, the training of ML emulators in weather and climate still relies on the use of real data datasets. Here we investigate whether the use of copula-based synthetically-augmented datasets improves the prediction of ML emulators for estimating the downwelling longwave radiation. Results show that bulk errors are cut by up to 75 % for the mean bias error (from 0.08 to -0.02 W m$^{-2}$) and by up to 62 % (from 1.17 to 0.44 W m$^{-2}$) for the mean absolute error, thus showing potential for improving the generalization of future ML emulators.