 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoordinate Linear Variance Reduction for Generalized Linear Programming
Paper and Code

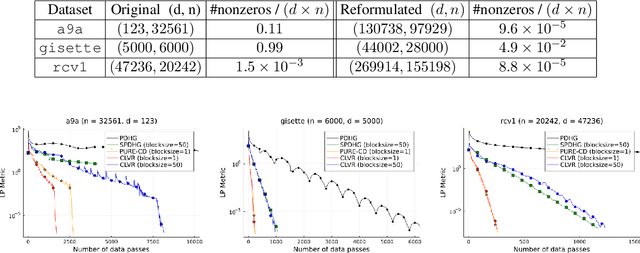
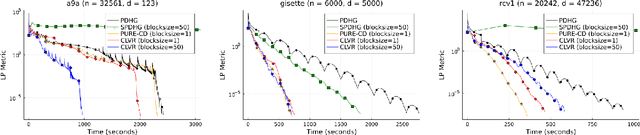
We study a class of generalized linear programs (GLP) in a large-scale setting, which includes possibly simple nonsmooth convex regularizer and simple convex set constraints. By reformulating GLP as an equivalent convex-concave min-max problem, we show that the linear structure in the problem can be used to design an efficient, scalable first-order algorithm, to which we give the name \emph{Coordinate Linear Variance Reduction} (\textsc{clvr}; pronounced "clever"). \textsc{clvr} is an incremental coordinate method with implicit variance reduction that outputs an \emph{affine combination} of the dual variable iterates. \textsc{clvr} yields improved complexity results for (GLP) that depend on the max row norm of the linear constraint matrix in (GLP) rather than the spectral norm. When the regularization terms and constraints are separable, \textsc{clvr} admits an efficient lazy update strategy that makes its complexity bounds scale with the number of nonzero elements of the linear constraint matrix in (GLP) rather than the matrix dimensions. We show that Distributionally Robust Optimization (DRO) problems with ambiguity sets based on both $f$-divergence and Wasserstein metrics can be reformulated as (GLPs) by introducing sparsely connected auxiliary variables. We complement our theoretical guarantees with numerical experiments that verify our algorithm's practical effectiveness, both in terms of wall-clock time and number of data passes.