 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional Temporal Attention Model for Video-based Person Re-identification
Paper and Code
Apr 10, 2019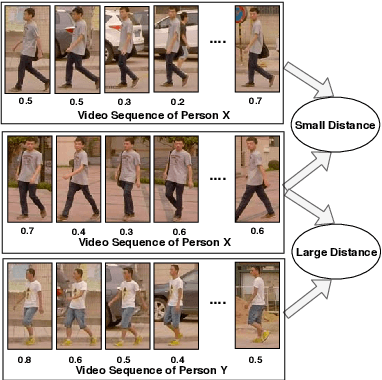
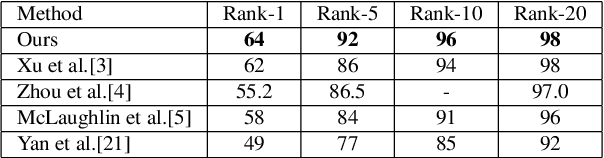
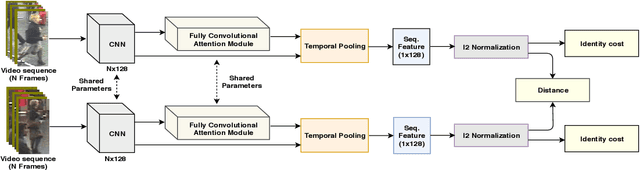
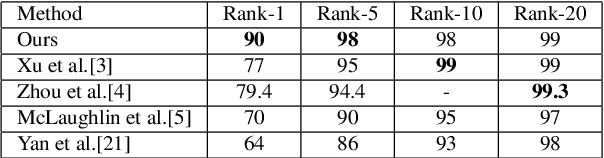
The goal of video-based person re-identification is to match two input videos, so that the distance of the two videos is small if two videos contain the same person. A common approach for person re-identification is to first extract image features for all frames in the video, then aggregate all the features to form a video-level feature. The video-level features of two videos can then be used to calculate the distance of the two videos. In this paper, we propose a temporal attention approach for aggregating frame-level features into a video-level feature vector for re-identification. Our method is motivated by the fact that not all frames in a video are equally informative. We propose a fully convolutional temporal attention model for generating the attention scores. Fully convolutional network (FCN) has been widely used in semantic segmentation for generating 2D output maps. In this paper, we formulate video based person re-identification as a sequence labeling problem like semantic segmentation. We establish a connection between them and modify FCN to generate attention scores to represent the importance of each frame. Extensive experiments on three different benchmark datasets (i.e. iLIDS-VID, PRID-2011 and SDU-VID) show that our proposed method outperforms other state-of-the-art approaches.