 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvex Calibrated Surrogates for the Multi-Label F-Measure
Paper and Code
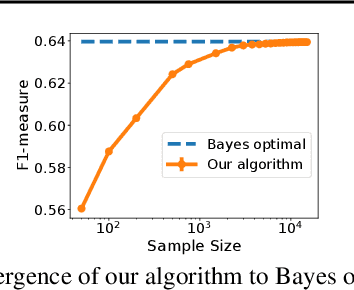
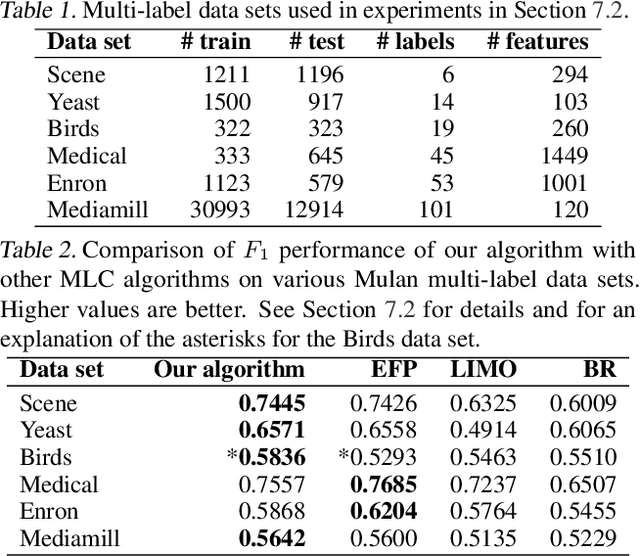
The F-measure is a widely used performance measure for multi-label classification, where multiple labels can be active in an instance simultaneously (e.g. in image tagging, multiple tags can be active in any image). In particular, the F-measure explicitly balances recall (fraction of active labels predicted to be active) and precision (fraction of labels predicted to be active that are actually so), both of which are important in evaluating the overall performance of a multi-label classifier. As with most discrete prediction problems, however, directly optimizing the F-measure is computationally hard. In this paper, we explore the question of designing convex surrogate losses that are calibrated for the F-measure -- specifically, that have the property that minimizing the surrogate loss yields (in the limit of sufficient data) a Bayes optimal multi-label classifier for the F-measure. We show that the F-measure for an $s$-label problem, when viewed as a $2^s \times 2^s$ loss matrix, has rank at most $s^2+1$, and apply a result of Ramaswamy et al. (2014) to design a family of convex calibrated surrogates for the F-measure. The resulting surrogate risk minimization algorithms can be viewed as decomposing the multi-label F-measure learning problem into $s^2+1$ binary class probability estimation problems. We also provide a quantitative regret transfer bound for our surrogates, which allows any regret guarantees for the binary problems to be transferred to regret guarantees for the overall F-measure problem, and discuss a connection with the algorithm of Dembczynski et al. (2013). Our experiments confirm our theoretical findings.