 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvex Biclustering
Paper and Code
Apr 15, 2016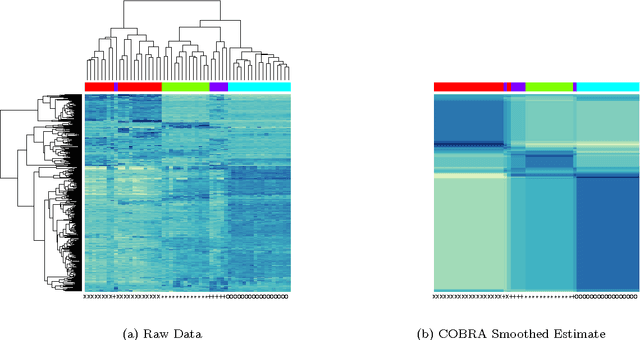
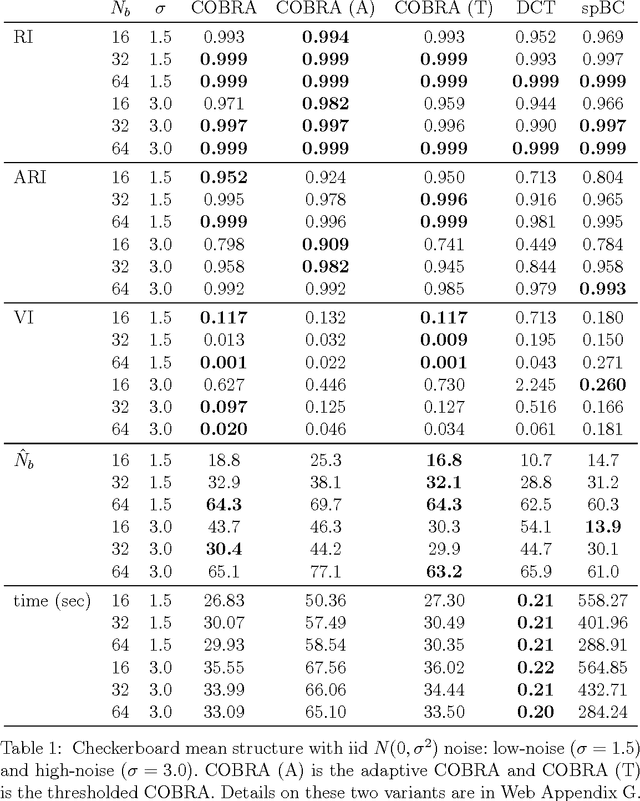

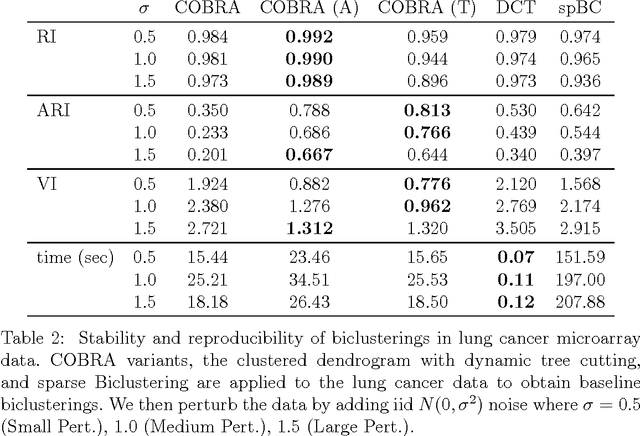
In the biclustering problem, we seek to simultaneously group observations and features. While biclustering has applications in a wide array of domains, ranging from text mining to collaborative filtering, the problem of identifying structure in high dimensional genomic data motivates this work. In this context, biclustering enables us to identify subsets of genes that are co-expressed only within a subset of experimental conditions. We present a convex formulation of the biclustering problem that possesses a unique global minimizer and an iterative algorithm, COBRA, that is guaranteed to identify it. Our approach generates an entire solution path of possible biclusters as a single tuning parameter is varied. We also show how to reduce the problem of selecting this tuning parameter to solving a trivial modification of the convex biclustering problem. The key contributions of our work are its simplicity, interpretability, and algorithmic guarantees - features that arguably are lacking in the current alternative algorithms. We demonstrate the advantages of our approach, which includes stably and reproducibly identifying biclusterings, on simulated and real microarray data.