 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence of Learning Dynamics in Stackelberg Games
Paper and Code
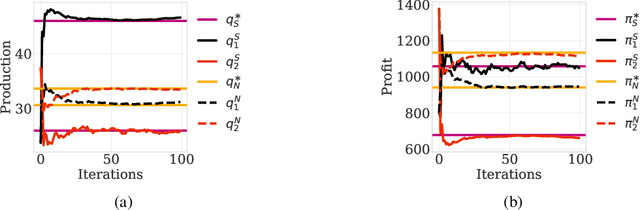
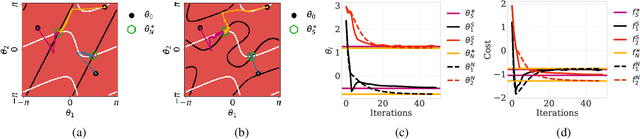
This paper investigates the convergence of learning dynamics in Stackelberg games. In the class of games we consider, there is a hierarchical game being played between a leader and a follower with continuous action spaces. We show that in zero-sum games, the only stable attractors of the Stackelberg gradient dynamics are Stackelberg equilibria. This insight allows us to develop a gradient-based update for the leader that converges to Stackelberg equilibria in zero-sum games and the set of stable attractors in general-sum games. We then consider a follower employing a gradient-play update rule instead of a best response strategy and propose a two-timescale algorithm with similar asymptotic convergence results. For this algorithm, we also provide finite-time high probability bounds for local convergence to a neighborhood of a stable Stackelberg equilibrium in general-sum games.