 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Wasserstein distances by Kernel norms with application to Compressive Statistical Learning
Paper and Code
Dec 17, 2021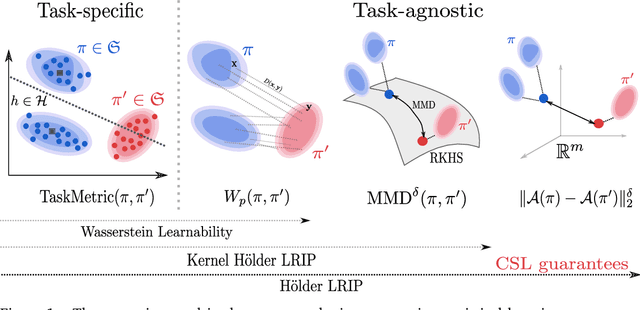
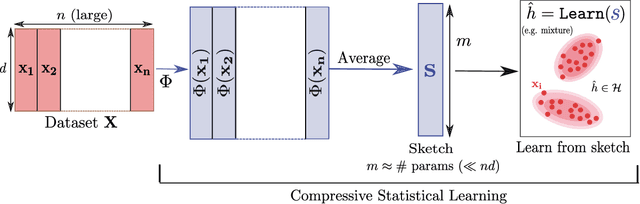

Comparing probability distributions is at the crux of many machine learning algorithms. Maximum Mean Discrepancies (MMD) and Optimal Transport distances (OT) are two classes of distances between probability measures that have attracted abundant attention in past years. This paper establishes some conditions under which the Wasserstein distance can be controlled by MMD norms. Our work is motivated by the compressive statistical learning (CSL) theory, a general framework for resource-efficient large scale learning in which the training data is summarized in a single vector (called sketch) that captures the information relevant to the considered learning task. Inspired by existing results in CSL, we introduce the H\"older Lower Restricted Isometric Property (H\"older LRIP) and show that this property comes with interesting guarantees for compressive statistical learning. Based on the relations between the MMD and the Wasserstein distance, we provide guarantees for compressive statistical learning by introducing and studying the concept of Wasserstein learnability of the learning task, that is when some task-specific metric between probability distributions can be bounded by a Wasserstein distance.